PDF) Incorporating representation learning and multihead attention
Por um escritor misterioso
Last updated 26 abril 2025

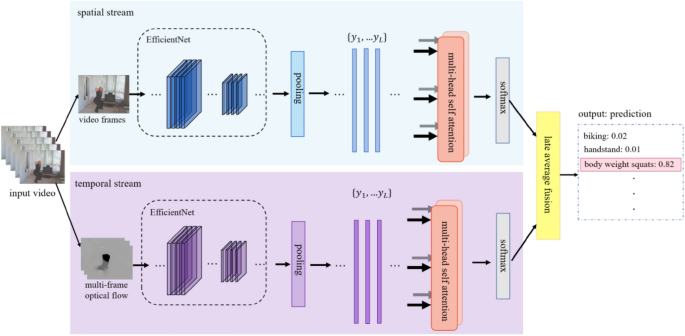
Multi-head attention-based two-stream EfficientNet for action recognition

How to Implement Multi-Head Attention from Scratch in TensorFlow and Keras
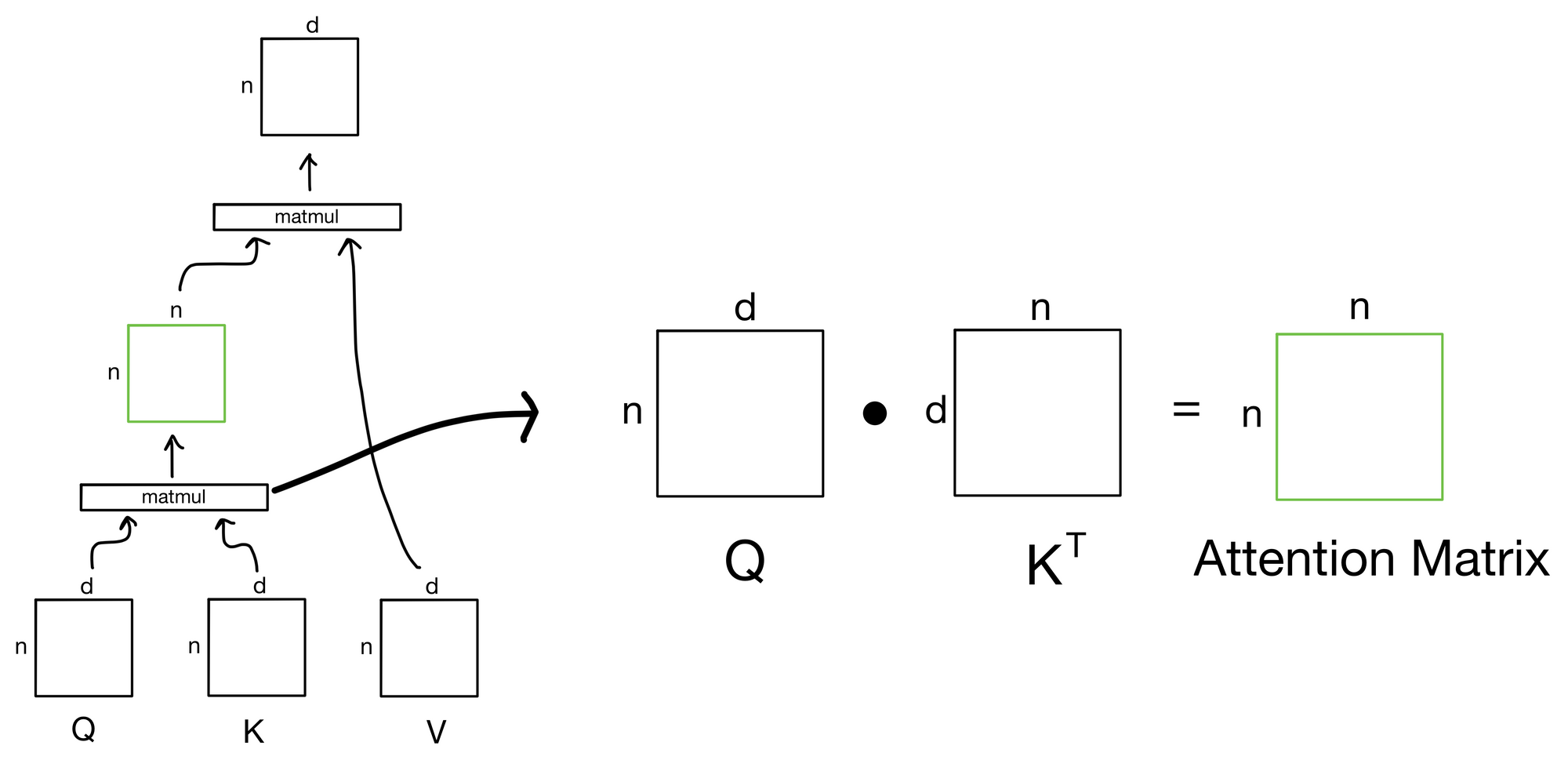
Explained: Multi-head Attention (Part 1)
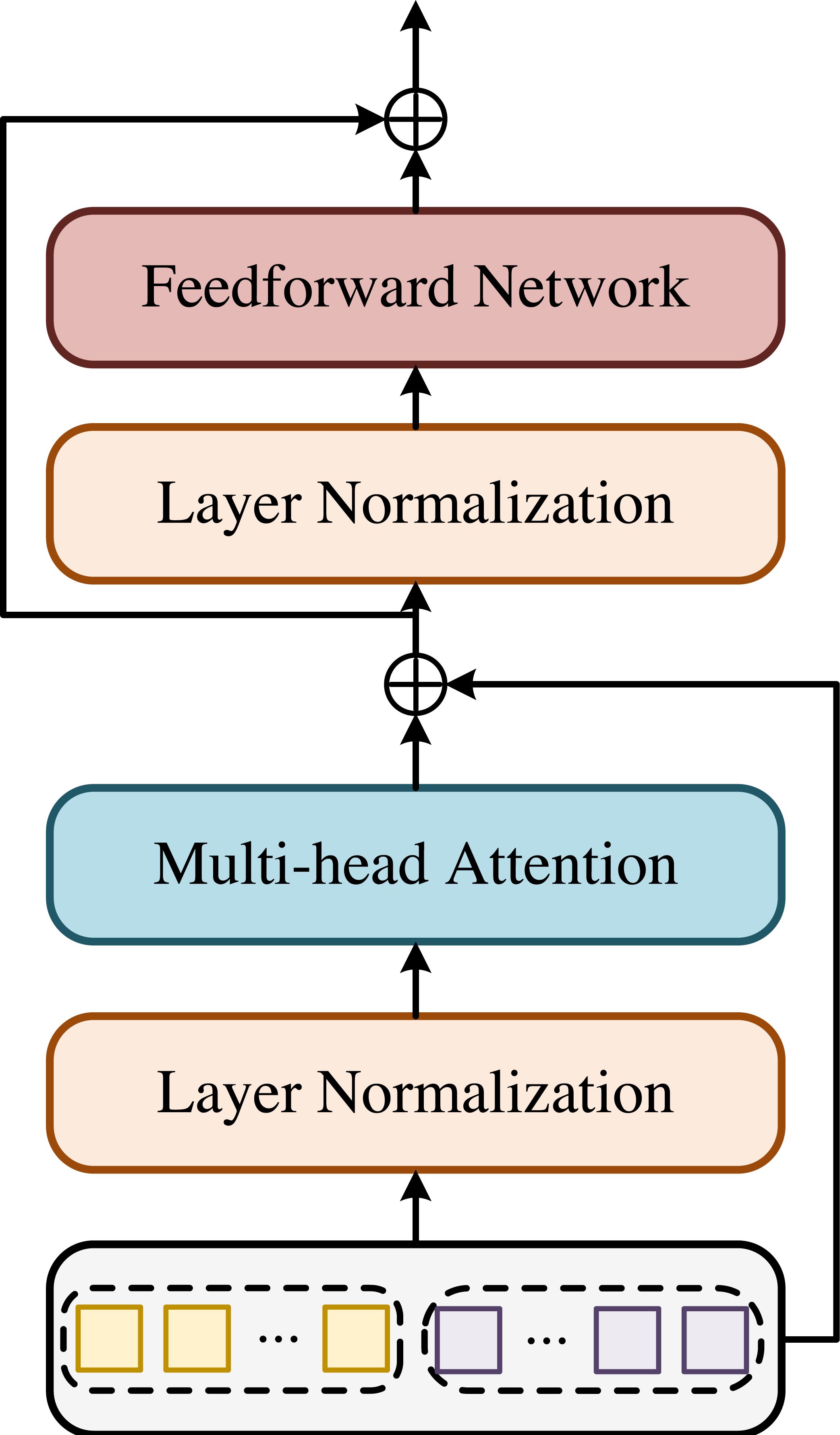
Analysis of the mixed teaching of college physical education based on the health big data and blockchain technology [PeerJ]

PDF] Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media

Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders – arXiv Vanity

RNN with Multi-Head Attention
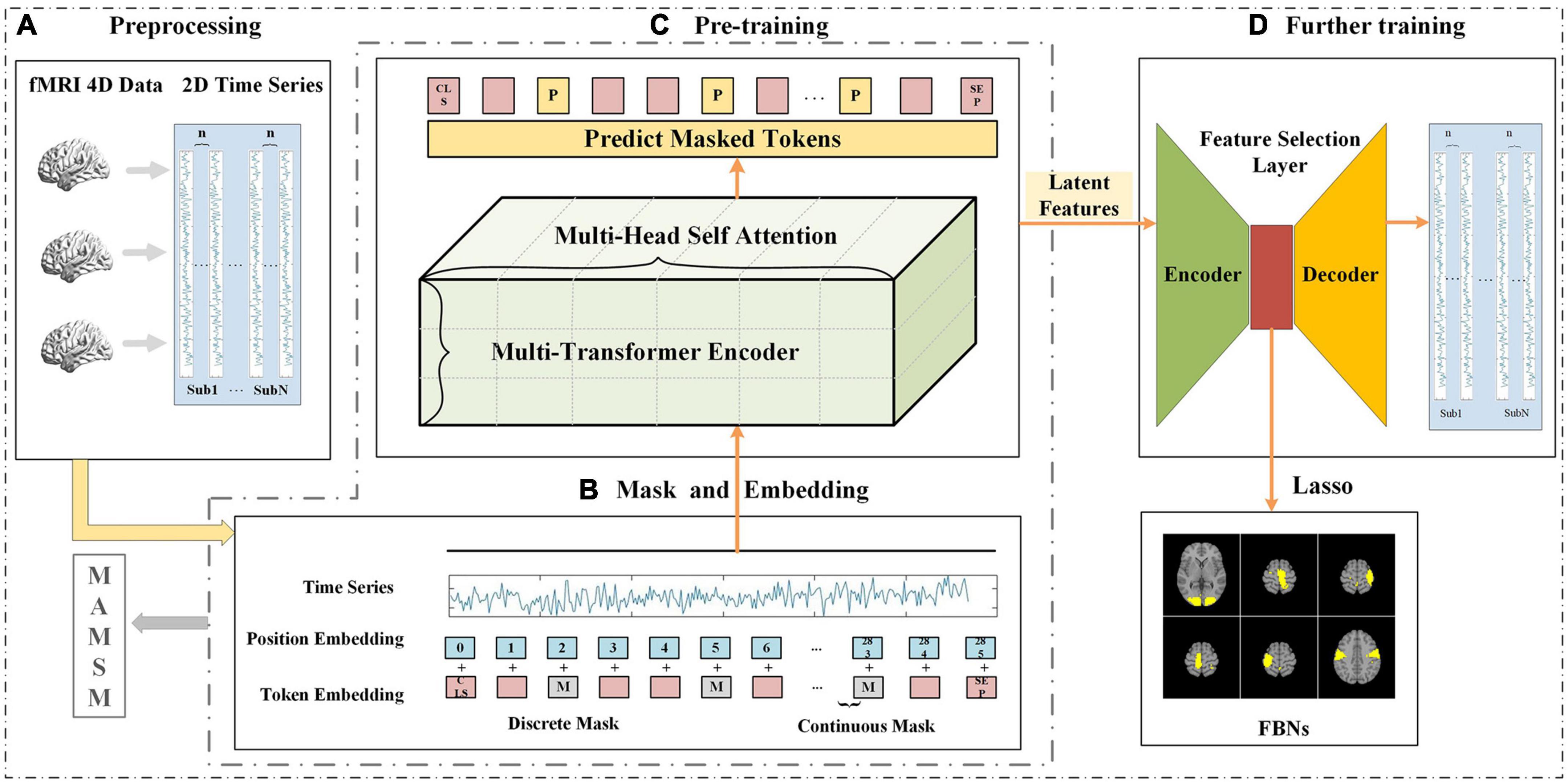
Frontiers Multi-head attention-based masked sequence model for mapping functional brain networks
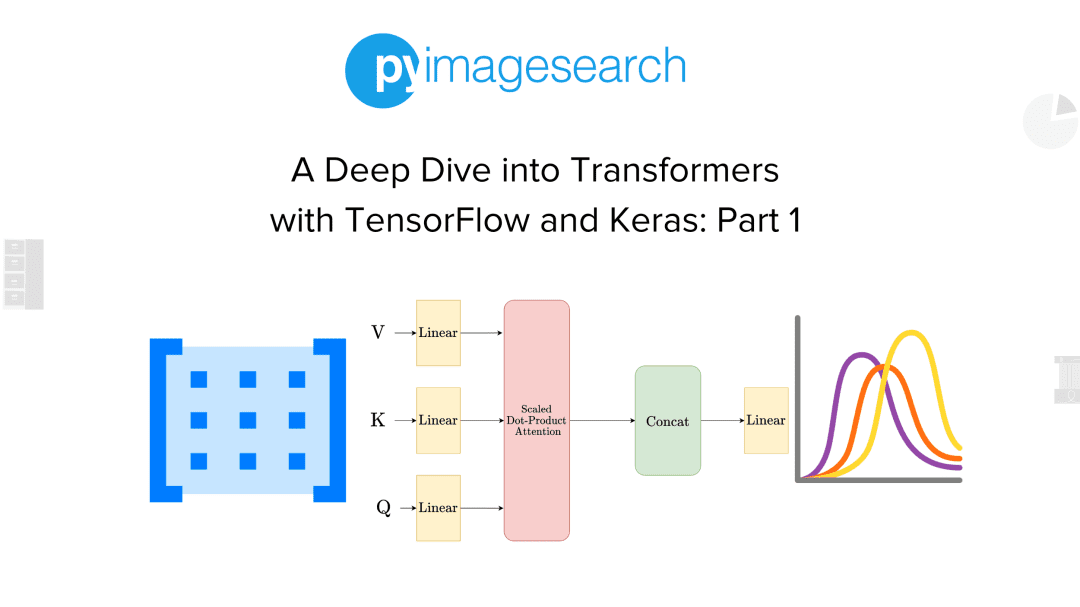
A Deep Dive into Transformers with TensorFlow and Keras: Part 1 - PyImageSearch
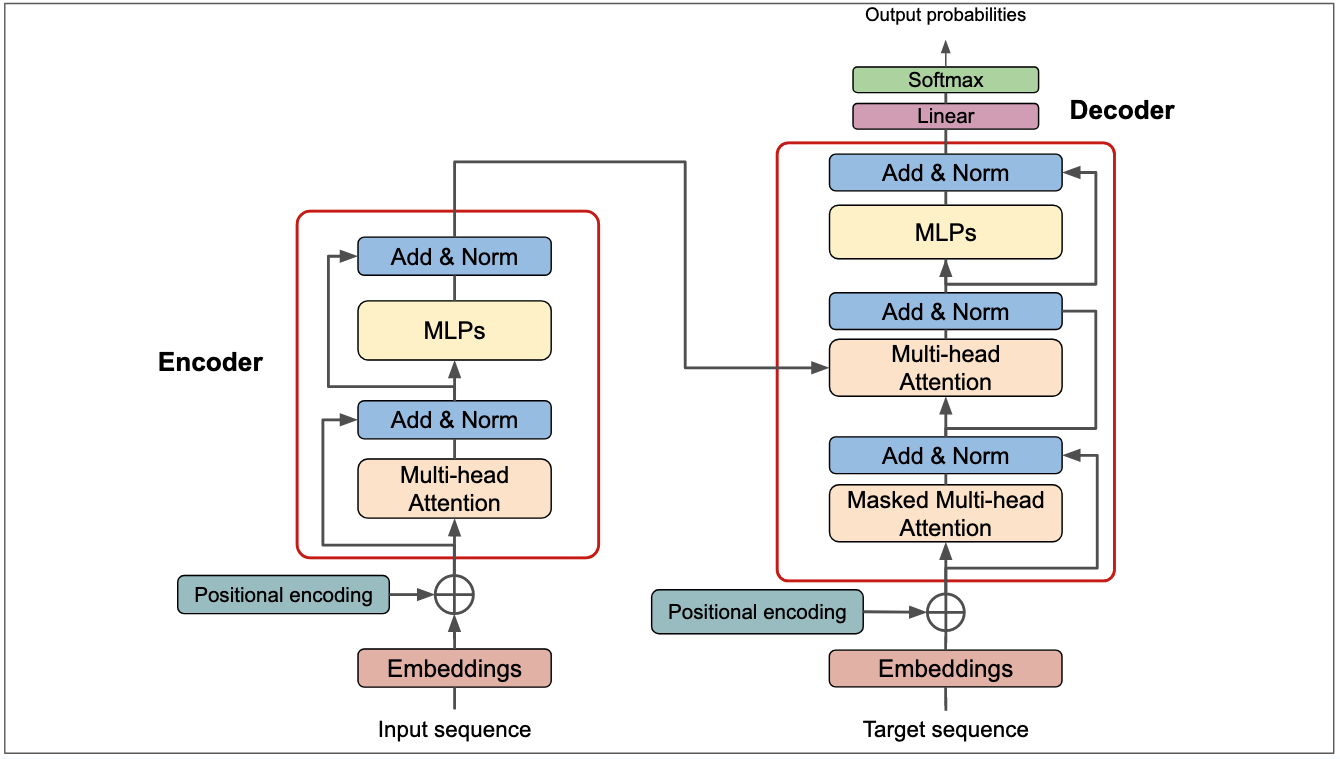
AI Research Blog - The Transformer Blueprint: A Holistic Guide to the Transformer Neural Network Architecture
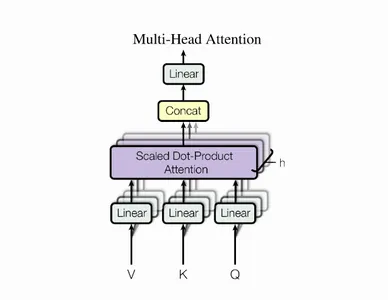
Understanding Attention Mechanisms Using Multi-Head Attention

PDF) Multi-Head Attention with Diversity for Learning Grounded Multilingual Multimodal Representations
Recomendado para você
-
 Examples of cross checking26 abril 2025
Examples of cross checking26 abril 2025 -
 EAL Circle Games for Reception26 abril 2025
EAL Circle Games for Reception26 abril 2025 -
 Fangyu Liu on X: Want to bootstrap your sentence similarity model26 abril 2025
Fangyu Liu on X: Want to bootstrap your sentence similarity model26 abril 2025 -
 1. Evaluating You-Attitude in Documents that Cross26 abril 2025
1. Evaluating You-Attitude in Documents that Cross26 abril 2025 -
 Handed a death sentence': UK doctor forced to return to Gaza from26 abril 2025
Handed a death sentence': UK doctor forced to return to Gaza from26 abril 2025 -
 Directions: Put a check mark (√) if the second sentence has26 abril 2025
Directions: Put a check mark (√) if the second sentence has26 abril 2025 -
 How to effectively cross-promote apps - The PickFu blog26 abril 2025
How to effectively cross-promote apps - The PickFu blog26 abril 2025 -
 PDF) Bi-Directional Evidence Linking Sentence Production and26 abril 2025
PDF) Bi-Directional Evidence Linking Sentence Production and26 abril 2025 -
 Metacommentary: Definition and Examples (2023)26 abril 2025
Metacommentary: Definition and Examples (2023)26 abril 2025 -
 7 Cross checking ideas teaching reading, reading strategies26 abril 2025
7 Cross checking ideas teaching reading, reading strategies26 abril 2025
você pode gostar
-
 PS4 Saint Seiya Soldiers' Soul (US)26 abril 2025
PS4 Saint Seiya Soldiers' Soul (US)26 abril 2025 -
Istanbul 13.02.2022. Love you guys ❤️26 abril 2025
-
 This guy was done with drift meme. - GIF - Imgur26 abril 2025
This guy was done with drift meme. - GIF - Imgur26 abril 2025 -
História de Vampiro:Jogo Anime APK (Android Game) - Baixar Grátis26 abril 2025
-
 Velozes & Furiosos 9 - Filme 2021 - AdoroCinema26 abril 2025
Velozes & Furiosos 9 - Filme 2021 - AdoroCinema26 abril 2025 -
 Review: 'New Mutants' #30 Celebrates In Style – COMICON26 abril 2025
Review: 'New Mutants' #30 Celebrates In Style – COMICON26 abril 2025 -
 Jogos de Agua e Fogo 726 abril 2025
Jogos de Agua e Fogo 726 abril 2025 -
Discuss Everything About Roblox Creepypasta Wiki26 abril 2025
-
 2022 engraçado Sakura Boruto наруто Camiseta Kaawaii Anime Roupas Ninja Dos Desenhos Animados Imprimir Pouco T-shirt das Meninas do Menino Roupa Dos Miúdos Rosa Topo26 abril 2025
2022 engraçado Sakura Boruto наруто Camiseta Kaawaii Anime Roupas Ninja Dos Desenhos Animados Imprimir Pouco T-shirt das Meninas do Menino Roupa Dos Miúdos Rosa Topo26 abril 2025 -
ATENÇÃO - E assim se nasce mais um - Família dos Chefes26 abril 2025


