Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Por um escritor misterioso
Last updated 26 abril 2025

Figure 1: Training AlphaZero for 700,000 steps. Elo ratings were computed from evaluation games between different players when given one second per move. a Performance of AlphaZero in chess, compared to 2016 TCEC world-champion program Stockfish. b Performance of AlphaZero in shogi, compared to 2017 CSA world-champion program Elmo. c Performance of AlphaZero in Go, compared to AlphaGo Lee and AlphaGo Zero (20 block / 3 day) (29). - "Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm"
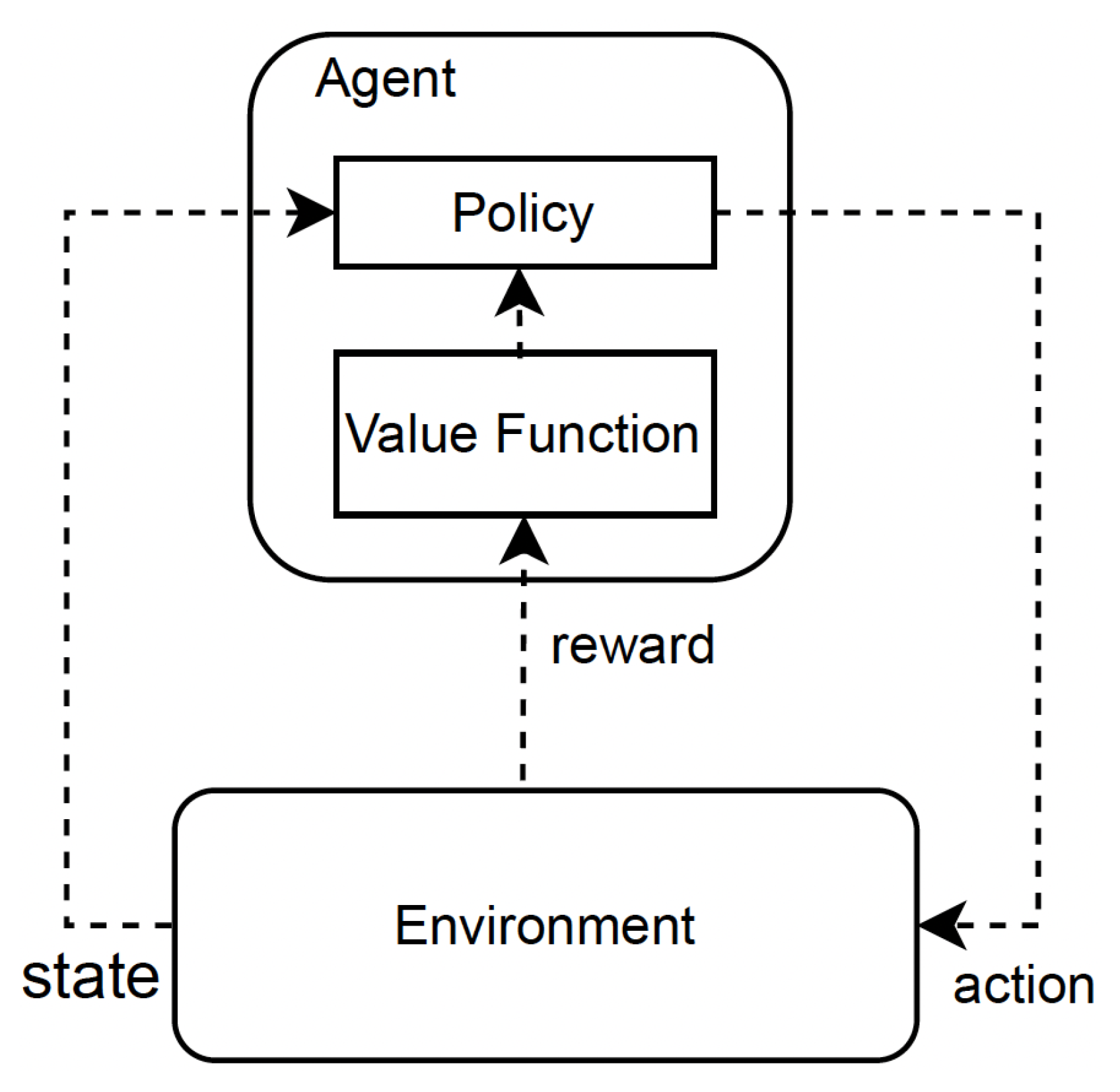
Resource Management for Internet of Things Environments
Create AI for your Own Board Game From Scratch — AlphaZero-Part 3, by Haryo Akbarianto Wibowo

All the important games artificial intelligence has conquered - TechTalks

Acquisition of chess knowledge in AlphaZero

MuZero - Wikipedia
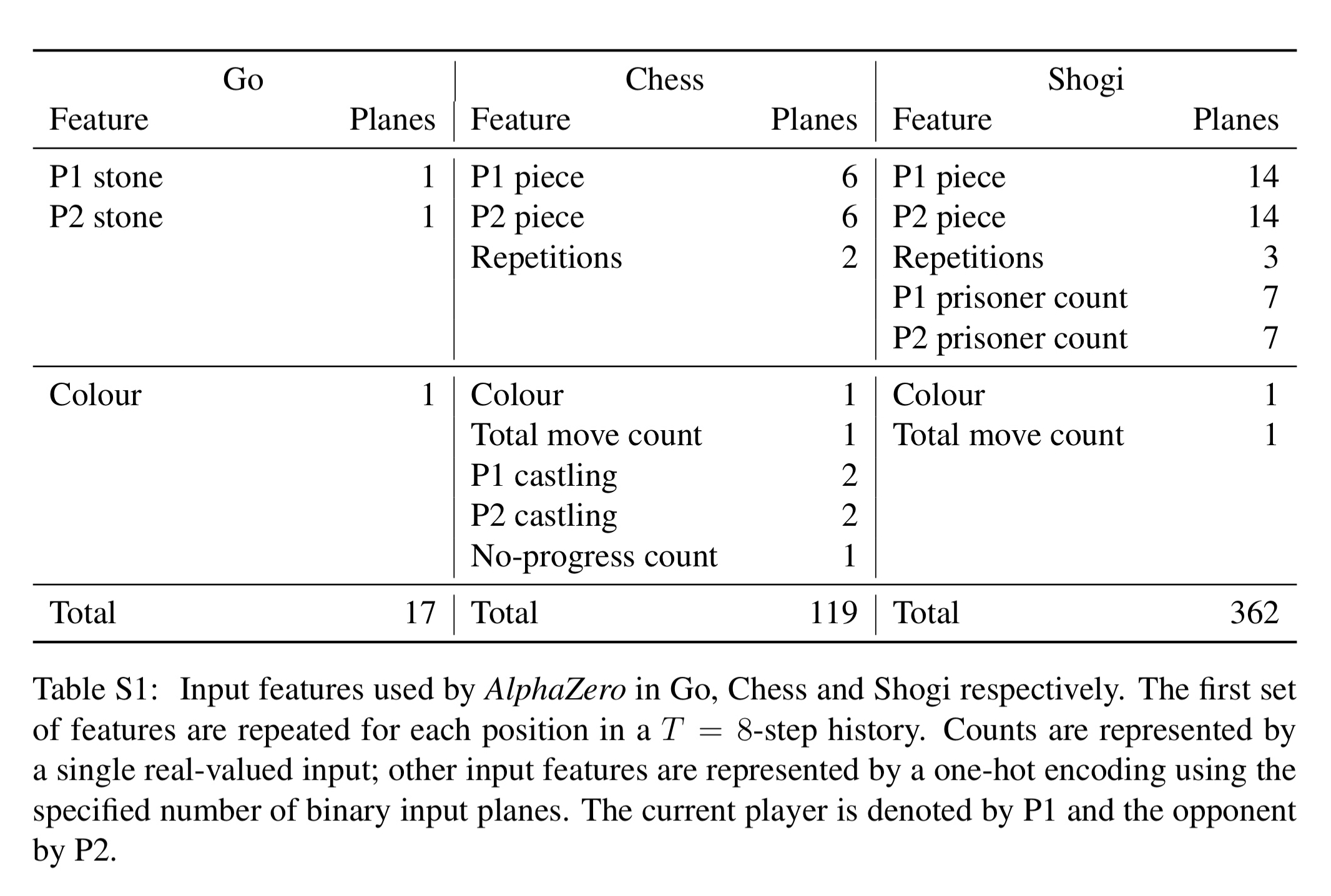
Mastering chess and shogi by self-play with a general reinforcement learning algorithm

MuZero figures out chess, rules and all
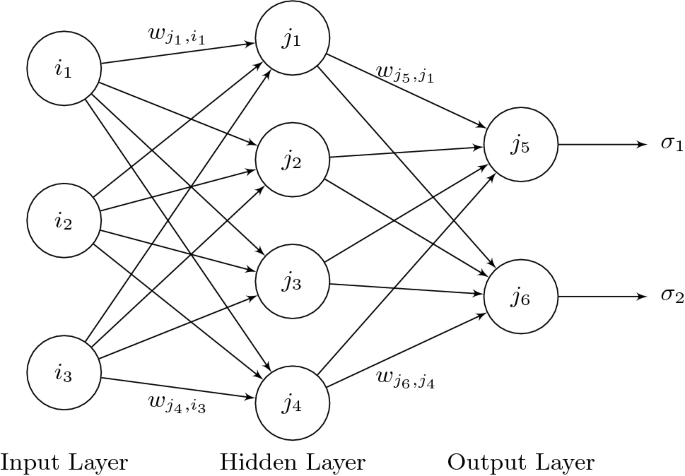
Reinforcement learning applied to games

Shogi - Wikipedia
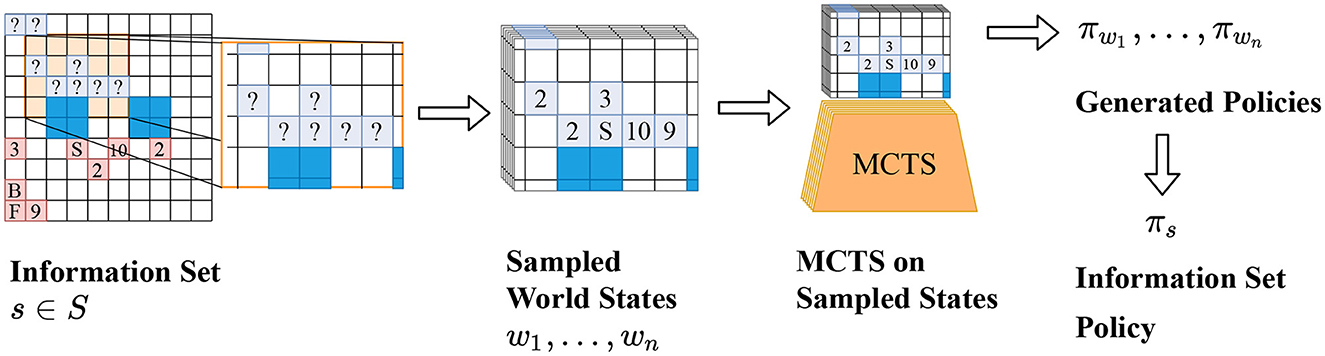
Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong
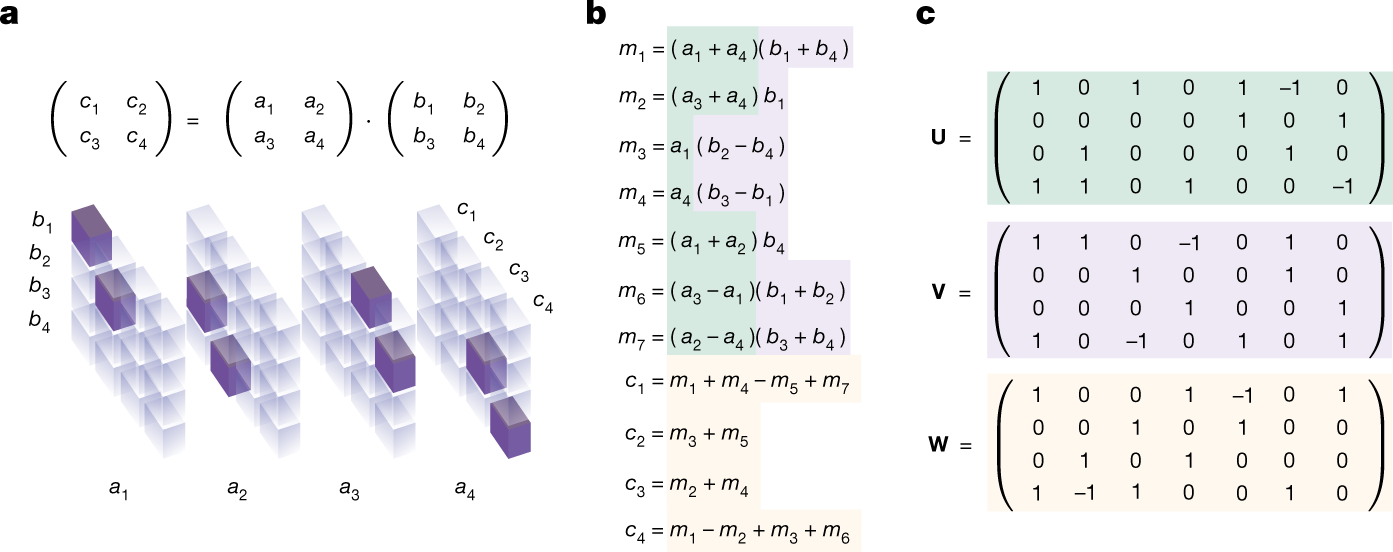
Discovering faster matrix multiplication algorithms with reinforcement learning

PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm

Figure 1 from Giraffe: Using Deep Reinforcement Learning to Play Chess

Reinforcement Learning, Fast and Slow: Trends in Cognitive Sciences

PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
Recomendado para você
-
 Reimagining Chess with AlphaZero, February 202226 abril 2025
Reimagining Chess with AlphaZero, February 202226 abril 2025 -
 AlphaZero Chess Engine: The Ultimate Guide26 abril 2025
AlphaZero Chess Engine: The Ultimate Guide26 abril 2025 -
 training - What does it mean for AlphaZero's network to be fully trained - Artificial Intelligence Stack Exchange26 abril 2025
training - What does it mean for AlphaZero's network to be fully trained - Artificial Intelligence Stack Exchange26 abril 2025 -
 LcZero ELO Rating List Estimates (Includes: AlphaZero, All Stockfish version releases, Stockfish Variants, Lc0 CUDA, and TCEC Div1+DivP Engines)26 abril 2025
LcZero ELO Rating List Estimates (Includes: AlphaZero, All Stockfish version releases, Stockfish Variants, Lc0 CUDA, and TCEC Div1+DivP Engines)26 abril 2025 -
 From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning26 abril 2025
From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning26 abril 2025 -
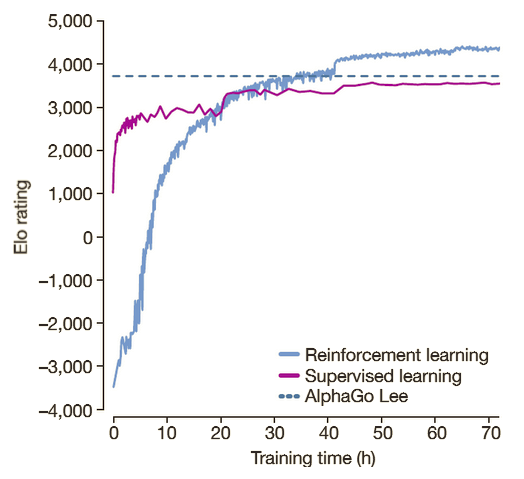 AlphaGo Zero Explained26 abril 2025
AlphaGo Zero Explained26 abril 2025 -
 Why DeepMind AlphaGo Zero is a game changer for AI research26 abril 2025
Why DeepMind AlphaGo Zero is a game changer for AI research26 abril 2025 -
 Was Alphazero beating Stockfish BS? • page 2/3 • General Chess Discussion •26 abril 2025
Was Alphazero beating Stockfish BS? • page 2/3 • General Chess Discussion •26 abril 2025 -
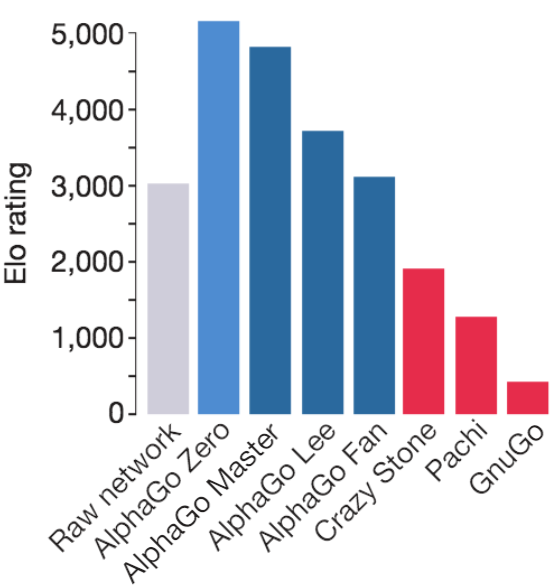 Love Letter to KataGo or: Go AI past, present, and future26 abril 2025
Love Letter to KataGo or: Go AI past, present, and future26 abril 2025 -
 AlphaZero paper peer-reviewed is available · Issue #2069 · leela-zero/leela- zero · GitHub26 abril 2025
AlphaZero paper peer-reviewed is available · Issue #2069 · leela-zero/leela- zero · GitHub26 abril 2025
você pode gostar
-
trouble tradução jin e namjoon|TikTok Search26 abril 2025
-
 Roblox Promo Codes and Free Items List April 2023, by Huskychetan26 abril 2025
Roblox Promo Codes and Free Items List April 2023, by Huskychetan26 abril 2025 -
 Help with my Mewtwo counters26 abril 2025
Help with my Mewtwo counters26 abril 2025 -
 Boss Costume Collection: Reshiram Plush - 13 ¼ In.26 abril 2025
Boss Costume Collection: Reshiram Plush - 13 ¼ In.26 abril 2025 -
 ✓ +450 Nomes masculinos italianos y su significado - ¡Te26 abril 2025
✓ +450 Nomes masculinos italianos y su significado - ¡Te26 abril 2025 -
 God of War games in order: By release date and timeline26 abril 2025
God of War games in order: By release date and timeline26 abril 2025 -
 Ousama Game The Animation Episode 12 H264 + 12 HEVC (H26526 abril 2025
Ousama Game The Animation Episode 12 H264 + 12 HEVC (H26526 abril 2025 -
 Kleki- Paint Tool Drawing programs, Nature art drawings, Best26 abril 2025
Kleki- Paint Tool Drawing programs, Nature art drawings, Best26 abril 2025 -
 Tênis: alto nível é fruto de, no mínimo, sete anos de treinamento sistemático - Esportividade - Guia de esporte de São Paulo e região26 abril 2025
Tênis: alto nível é fruto de, no mínimo, sete anos de treinamento sistemático - Esportividade - Guia de esporte de São Paulo e região26 abril 2025 -
 Etimologia 1000 Palavras Grego - 1000 Grego Palavras26 abril 2025
Etimologia 1000 Palavras Grego - 1000 Grego Palavras26 abril 2025
