Why DeepMind AlphaGo Zero is a game changer for AI research
Por um escritor misterioso
Last updated 25 abril 2025

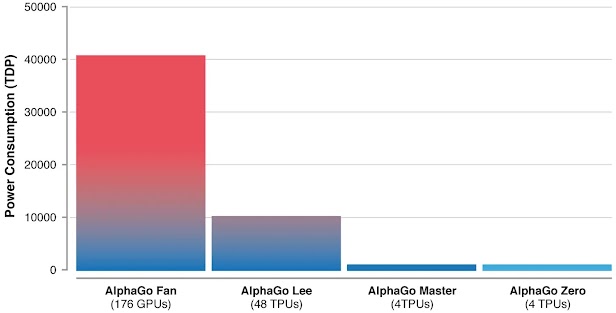
DeepMind AlphaGo Zero was able to defeat its predecessor in only three days time with lesser processing power than AlphaGo
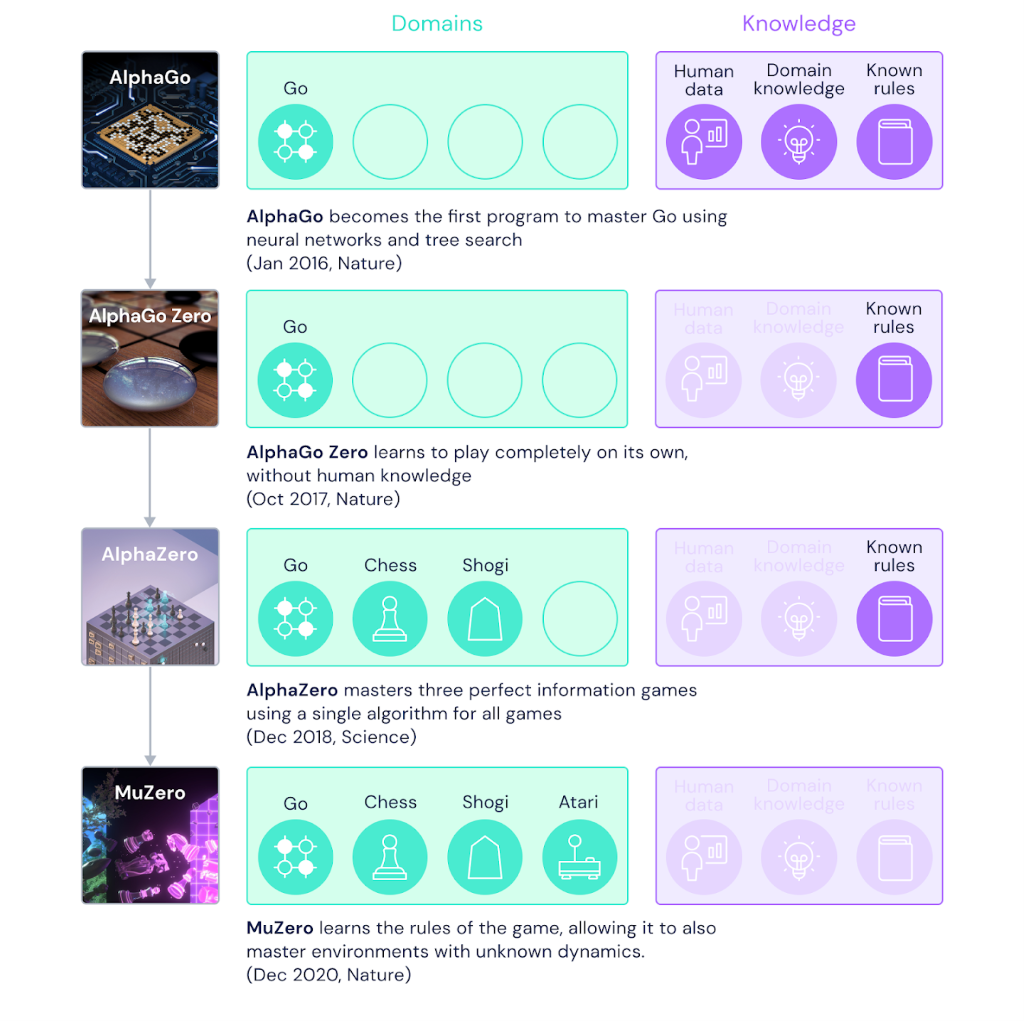
⚪️ ⚫️ Edge#56: DeepMind's MuZero that Mastered Go, Chess, Shogi and Atari Without Knowing the Rules

Is DeepMind's new reinforcement learning system a step toward general AI? - TechTalks

This More Powerful Version of AlphaGo Learns On Its Own

DeepMind's New AI Teaches Itself Chess, Beats Grandmaster
AlphaGo Zero: Starting from scratch - Google DeepMind
Why DeepMind AlphaGo Zero is a game changer for AI research
AlphaGo: How AI Mastered the Game of Go, by Diego Unzueta

This More Powerful Version of AlphaGo Learns On Its Own

What does DeepMind's latest publication mean for A.I.?, by Axel Sooriah
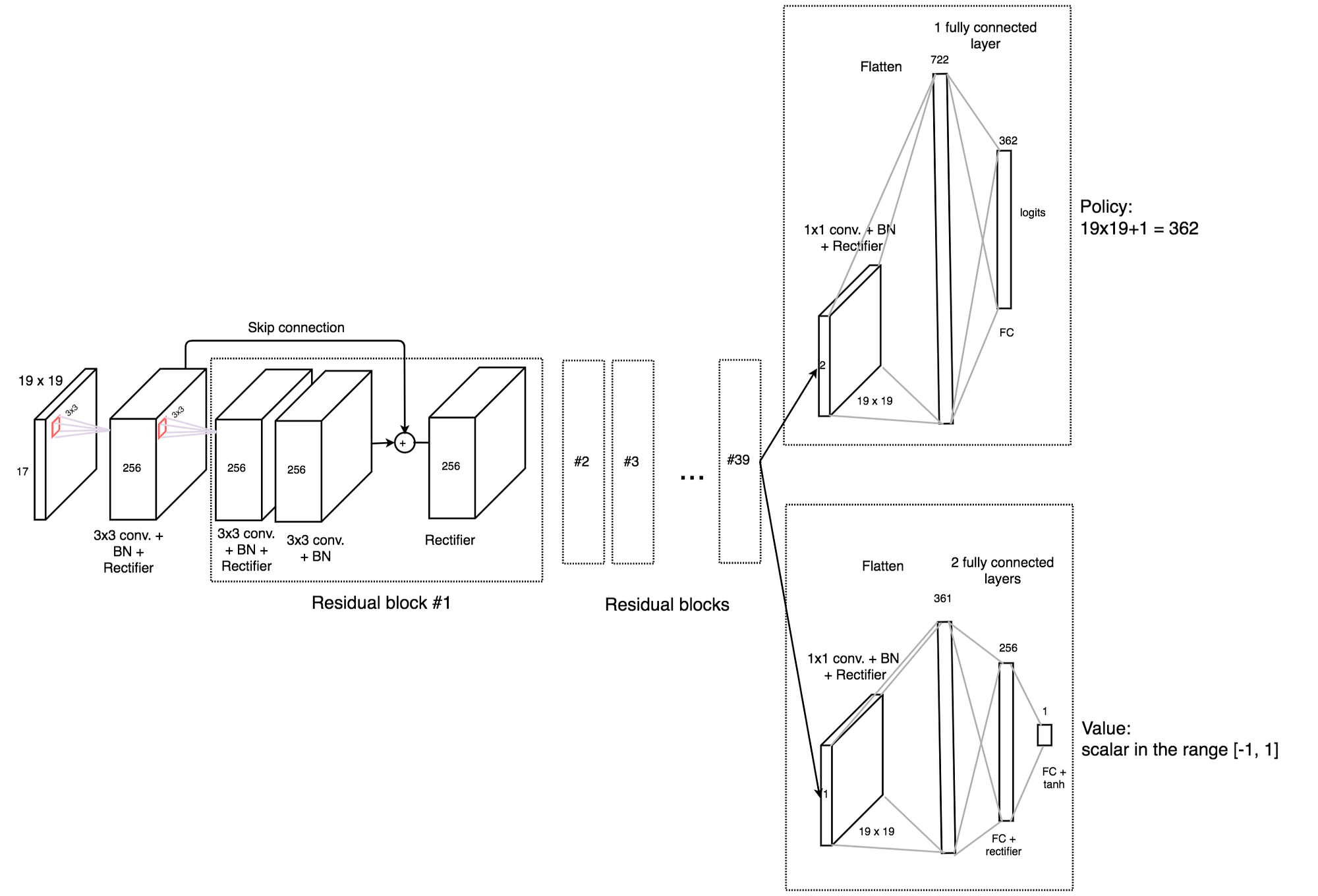
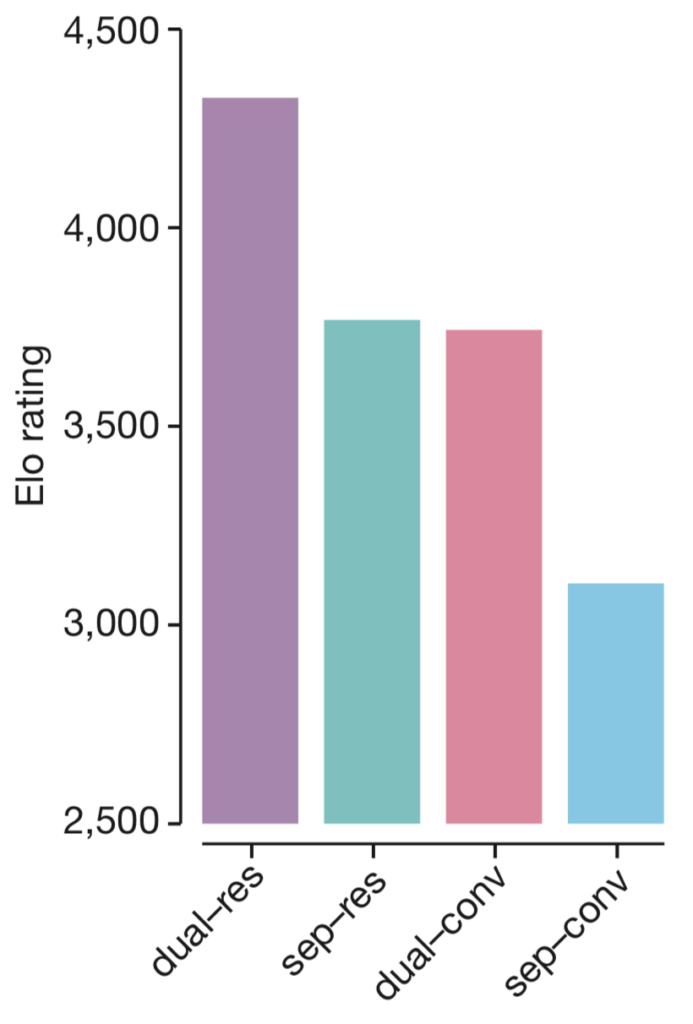
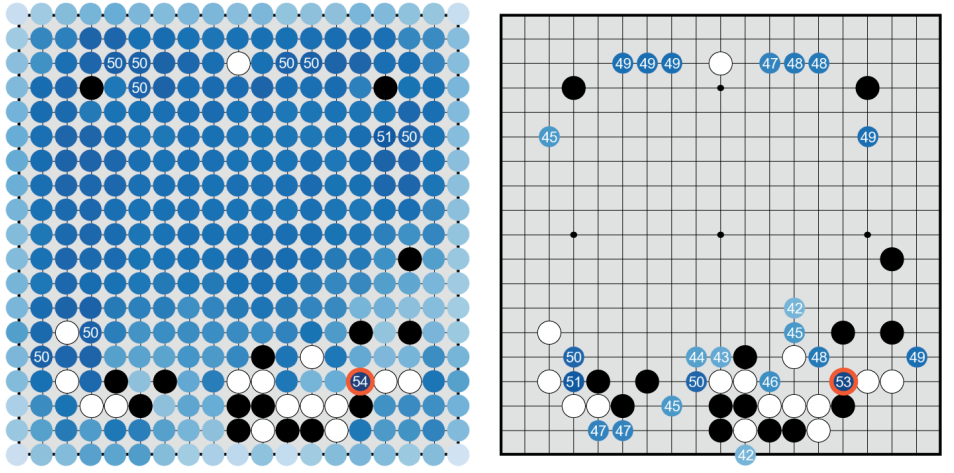
AlphaGo Zero — a game changer. (How it works?), by Jonathan Hui

Why DeepMind AlphaGo Zero is a game changer for AI research
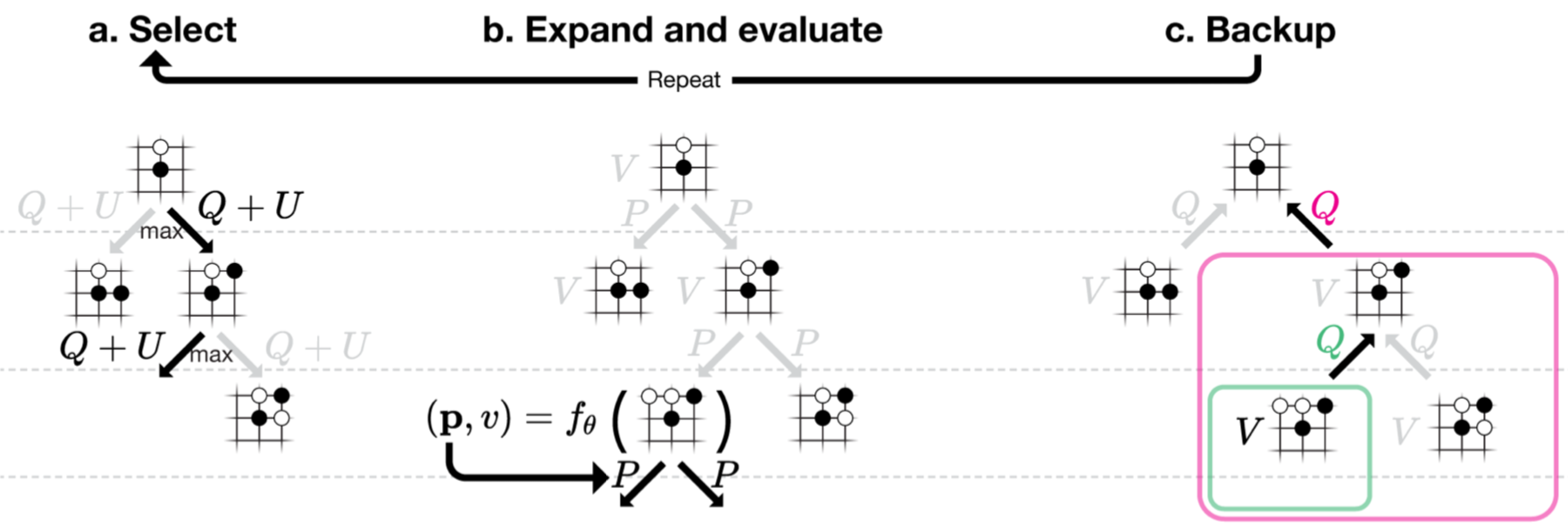
DeepMind's AlphaZero and The Real World

The AI That Has Nothing to Learn From Humans - The Atlantic
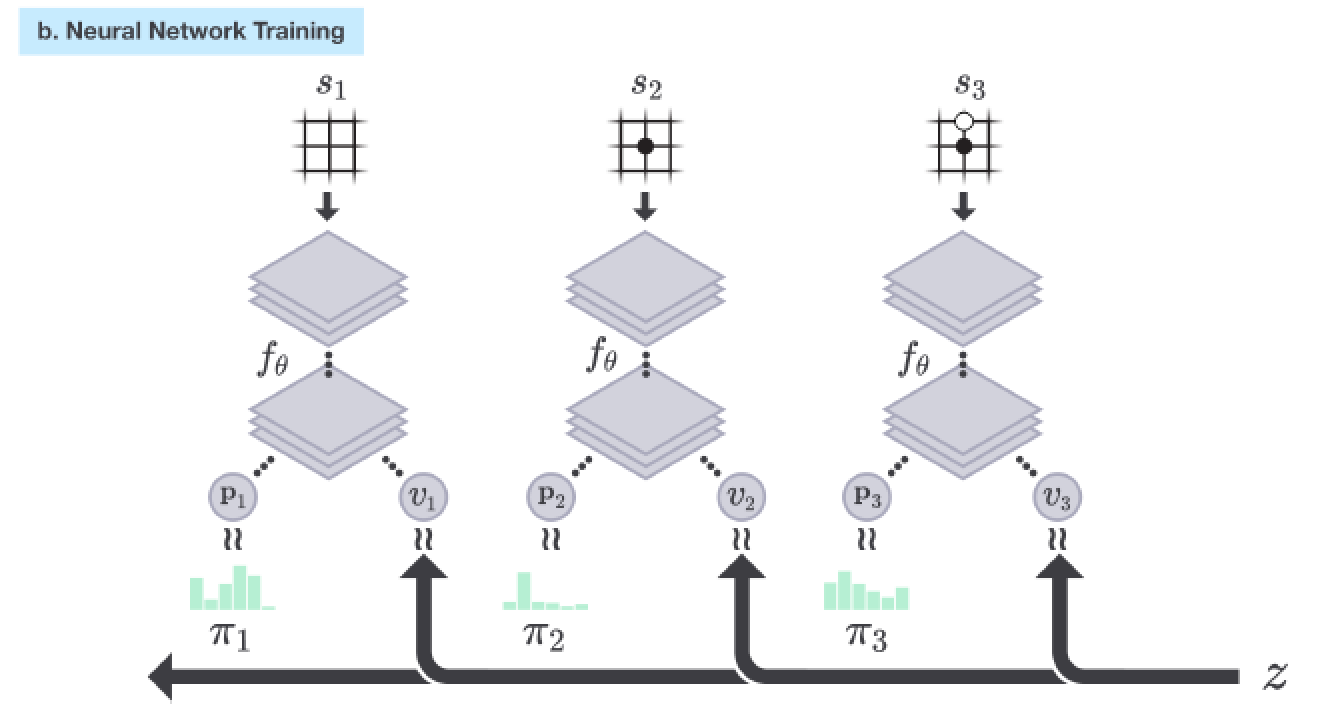
AlphaGo Zero — a game changer. (How it works?), by Jonathan Hui

Google creates AI that can teach itself and 'isn't constrained by the limits of human knowledge', The Independent
Recomendado para você
-
 Acquisition of chess knowledge in AlphaZero25 abril 2025
Acquisition of chess knowledge in AlphaZero25 abril 2025 -
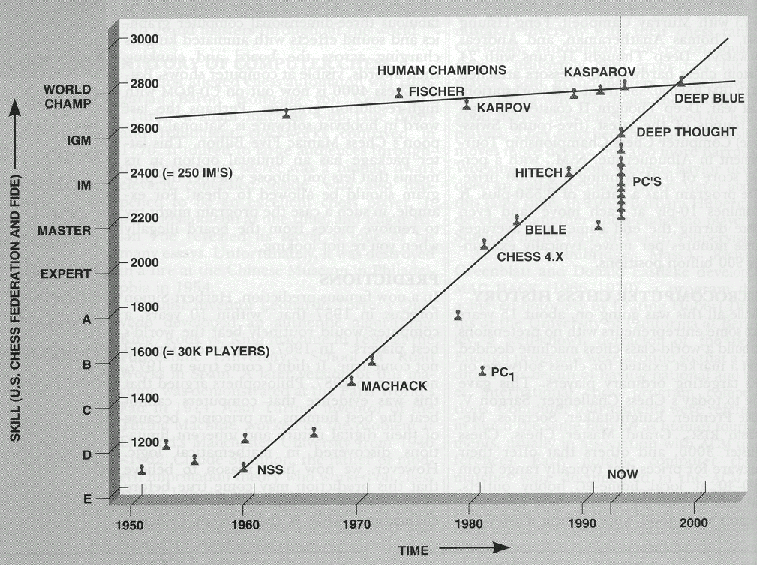 Time for AI to cross the human performance range in chess – AI Impacts25 abril 2025
Time for AI to cross the human performance range in chess – AI Impacts25 abril 2025 -
 Chess's New Best Player Is A Fearless, Swashbuckling Algorithm25 abril 2025
Chess's New Best Player Is A Fearless, Swashbuckling Algorithm25 abril 2025 -
 Google's AlphaZero Destroys Stockfish In 100-Game Match25 abril 2025
Google's AlphaZero Destroys Stockfish In 100-Game Match25 abril 2025 -
 Did AlphaZero also have to learn that each piece has a value? - Chess Stack Exchange25 abril 2025
Did AlphaZero also have to learn that each piece has a value? - Chess Stack Exchange25 abril 2025 -
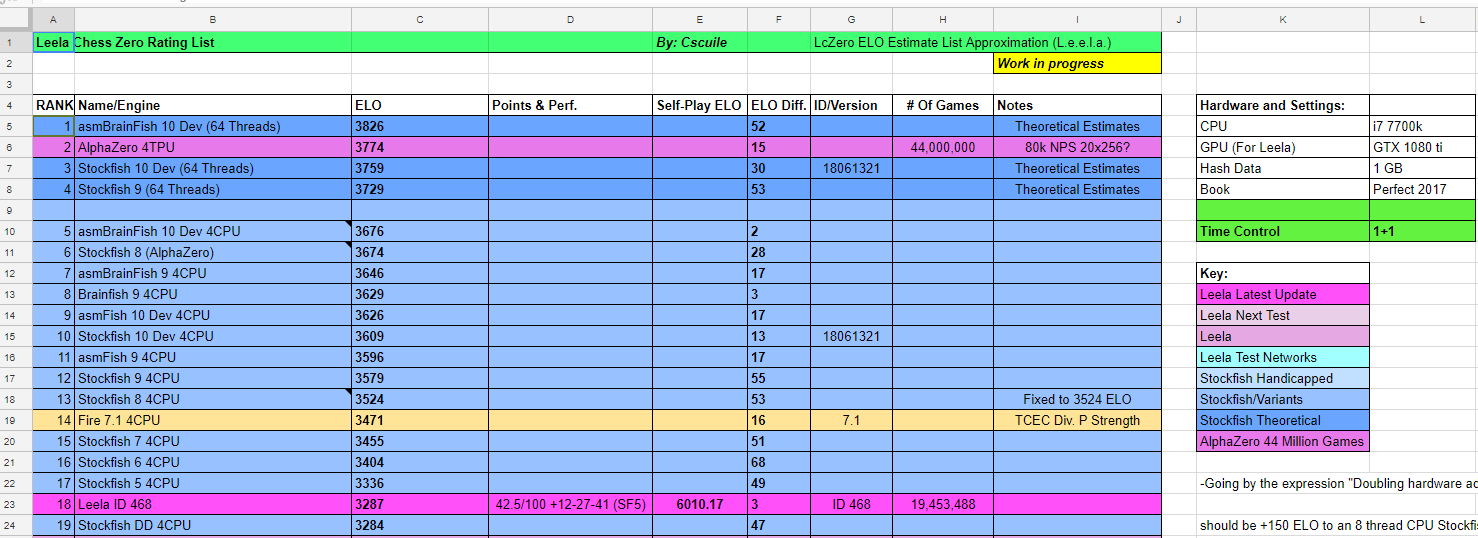 Alpha Zero vs Stockfish, vs Leela - Chess Forums25 abril 2025
Alpha Zero vs Stockfish, vs Leela - Chess Forums25 abril 2025 -
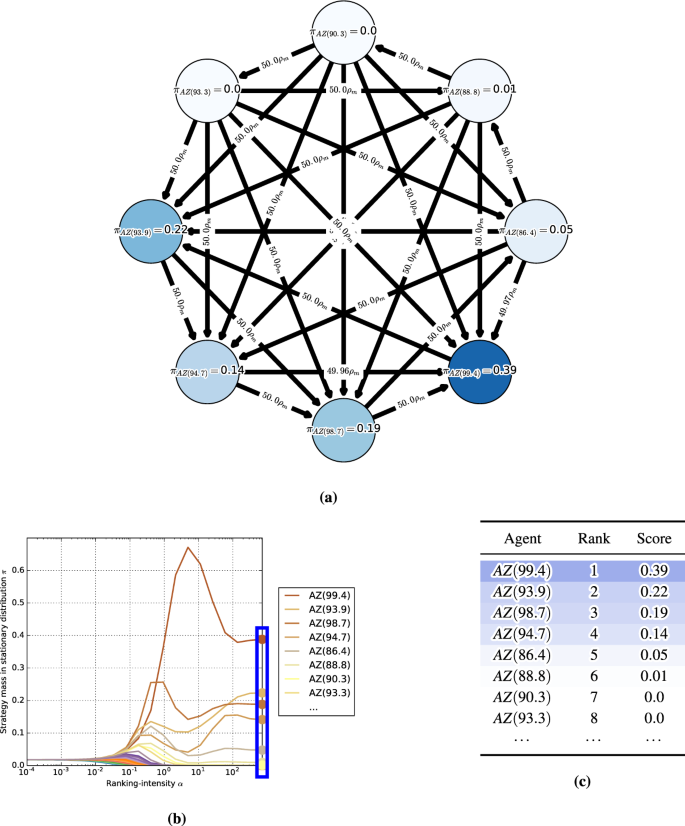 α-Rank: Multi-Agent Evaluation by Evolution25 abril 2025
α-Rank: Multi-Agent Evaluation by Evolution25 abril 2025 -
 Evans Gambit on The Highest Level25 abril 2025
Evans Gambit on The Highest Level25 abril 2025 -
 Chess: Magnus Carlsen scores in Alphazero style in fresh record hunt, Magnus Carlsen25 abril 2025
Chess: Magnus Carlsen scores in Alphazero style in fresh record hunt, Magnus Carlsen25 abril 2025 -
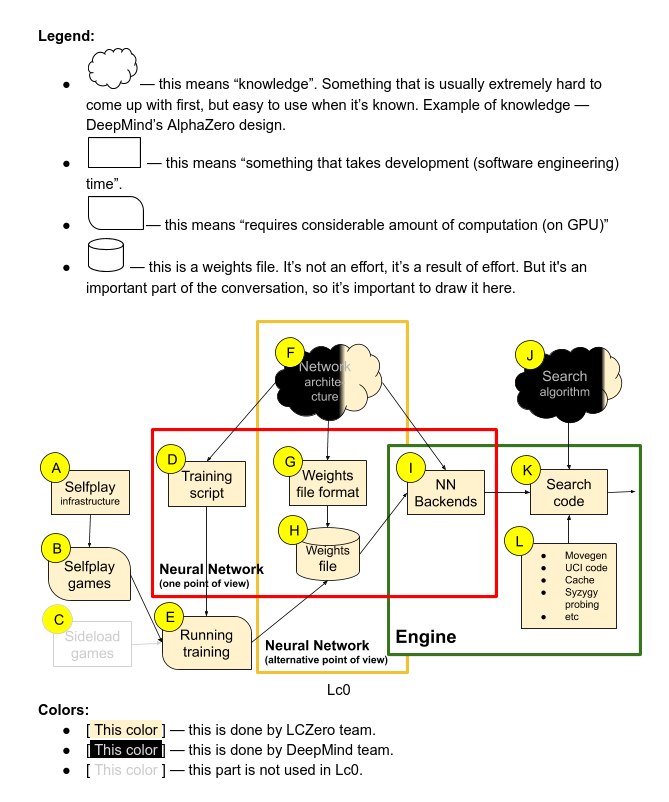 Leela Chess Zero - Chessprogramming wiki25 abril 2025
Leela Chess Zero - Chessprogramming wiki25 abril 2025
você pode gostar
-
 TÊNIS CONVERSE ALL STAR COURO ORIGINAL PRETO CT04480002 - Via Colors - Calçapé Calçados25 abril 2025
TÊNIS CONVERSE ALL STAR COURO ORIGINAL PRETO CT04480002 - Via Colors - Calçapé Calçados25 abril 2025 -
 Where to buy the Nvidia RTX 4060 Ti: Specs, price, release date25 abril 2025
Where to buy the Nvidia RTX 4060 Ti: Specs, price, release date25 abril 2025 -
 Evil dead hi-res stock photography and images - Alamy25 abril 2025
Evil dead hi-res stock photography and images - Alamy25 abril 2025 -
Immortal Chess Games : Petrosian vs Estrin Moscow 1968, Immortal Chess Games : Petrosian vs Estrin Moscow 1968, By Ecoachess25 abril 2025
-
 Ludwig Deglmann (Bayern) Schach 1. BL Herren 2008 2009, Schachsport, Denksport, Einzelbild München25 abril 2025
Ludwig Deglmann (Bayern) Schach 1. BL Herren 2008 2009, Schachsport, Denksport, Einzelbild München25 abril 2025 -
 Akatsuki Naruto Amino25 abril 2025
Akatsuki Naruto Amino25 abril 2025 -
 0œ25 abril 2025
0œ25 abril 2025 -
 Monster Hunter Series Image by Ryuuta (Ipse) #1391394 - Zerochan Anime Image Board25 abril 2025
Monster Hunter Series Image by Ryuuta (Ipse) #1391394 - Zerochan Anime Image Board25 abril 2025 -
 Create a Gacha Ocs Tier List - TierMaker25 abril 2025
Create a Gacha Ocs Tier List - TierMaker25 abril 2025 -
 Ditto (Pokemon) by VGAfanatic on DeviantArt25 abril 2025
Ditto (Pokemon) by VGAfanatic on DeviantArt25 abril 2025
