XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 26 abril 2025

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.

Papers With Code (Free Resource of Machine Learning Papers and
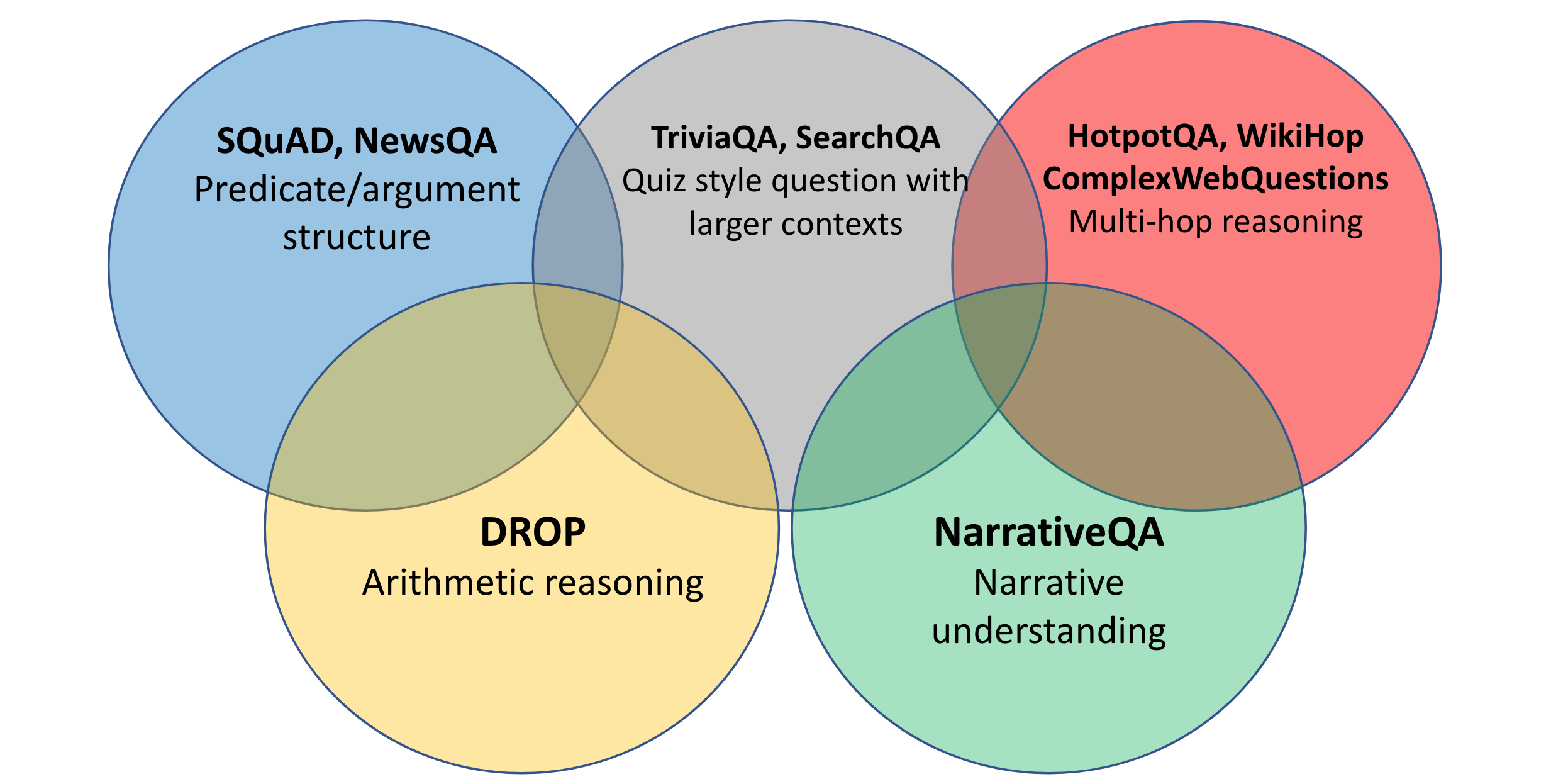
Multi-domain Multilingual Question Answering
XQuAD Dataset Papers With Code

SQuAD2.0 Benchmark (Question Answering)
GitHub - google-deepmind/xquad
ACL Best Paper: Tricky Stanford DataSet Adds Questions That Don't
.png)
How to train YOLOv8 on a custom Dataset — Picsellia

Papers with code or without code? Impact of GitHub repository

PDF] JaQuAD: Japanese Question Answering Dataset for Machine
Recomendado para você
-
AICE-OQ - Unit-1, PDF, Fuel Injection26 abril 2025
-
 Solved PHYS-48-40278-F20) Assignments Conceptual Questions26 abril 2025
Solved PHYS-48-40278-F20) Assignments Conceptual Questions26 abril 2025 -
 Automobile Engineering MCQ (Multiple Choice Questions) - Sanfoundry26 abril 2025
Automobile Engineering MCQ (Multiple Choice Questions) - Sanfoundry26 abril 2025 -
 PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES26 abril 2025
PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES26 abril 2025 -
 SOLUTION: Mechanical engineering interview questions pdf - Studypool26 abril 2025
SOLUTION: Mechanical engineering interview questions pdf - Studypool26 abril 2025 -
 50 Most Important RRB ALP Heat Engine Trade Questions PDF26 abril 2025
50 Most Important RRB ALP Heat Engine Trade Questions PDF26 abril 2025 -
 Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu26 abril 2025
Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu26 abril 2025 -
Solved could you answer this questions by typing please.26 abril 2025
-
 Confluence Mobile - Confluence26 abril 2025
Confluence Mobile - Confluence26 abril 2025 -
 Question and answers Mechanical Engg Simple Notes ,Solved problems and Videos26 abril 2025
Question and answers Mechanical Engg Simple Notes ,Solved problems and Videos26 abril 2025


você pode gostar
-
 The Sims Resource - Tokio (La casa de papel)26 abril 2025
The Sims Resource - Tokio (La casa de papel)26 abril 2025 -
 O Inferno de Dante26 abril 2025
O Inferno de Dante26 abril 2025 -
 M.Mokiato🇲🇽🐍 (@mistermokiato) / X26 abril 2025
M.Mokiato🇲🇽🐍 (@mistermokiato) / X26 abril 2025 -
 YESASIA: Image Gallery - Fairy Ranmaru: Anata no Kokoro Otasuke Shimasu Vol. 1 (DVD) (Japan Version)26 abril 2025
YESASIA: Image Gallery - Fairy Ranmaru: Anata no Kokoro Otasuke Shimasu Vol. 1 (DVD) (Japan Version)26 abril 2025 -
Indigo Papers - Caderno Luluca, universitário, caderno de desenho e A5. Fofinho! #encadernaçãoartesanal #encadernaçãopersonalizada #cadernopersonalizados #indigopapers26 abril 2025
-
 Baraka & Mileena Share their Experience with Tarkat Disease26 abril 2025
Baraka & Mileena Share their Experience with Tarkat Disease26 abril 2025 -
 Vetores de Setor De Energia Eólica Moinho De Vento Gerador De Energia e mais imagens de Eletricidade - iStock26 abril 2025
Vetores de Setor De Energia Eólica Moinho De Vento Gerador De Energia e mais imagens de Eletricidade - iStock26 abril 2025 -
foryourpage #lyriicsmusiics26 abril 2025
-
News Digest for the Week of January 1026 abril 2025
-
 Qui Gon Jinn by editsulli on DeviantArt26 abril 2025
Qui Gon Jinn by editsulli on DeviantArt26 abril 2025

