DeepMind: the existence proof for RL at scale, by Nathan Lambert
Por um escritor misterioso
Last updated 12 março 2025


Arun Rao (@rao_hacker_one) / X

Why we need transparency and open-source action around reward models., Nathan Lambert posted on the topic
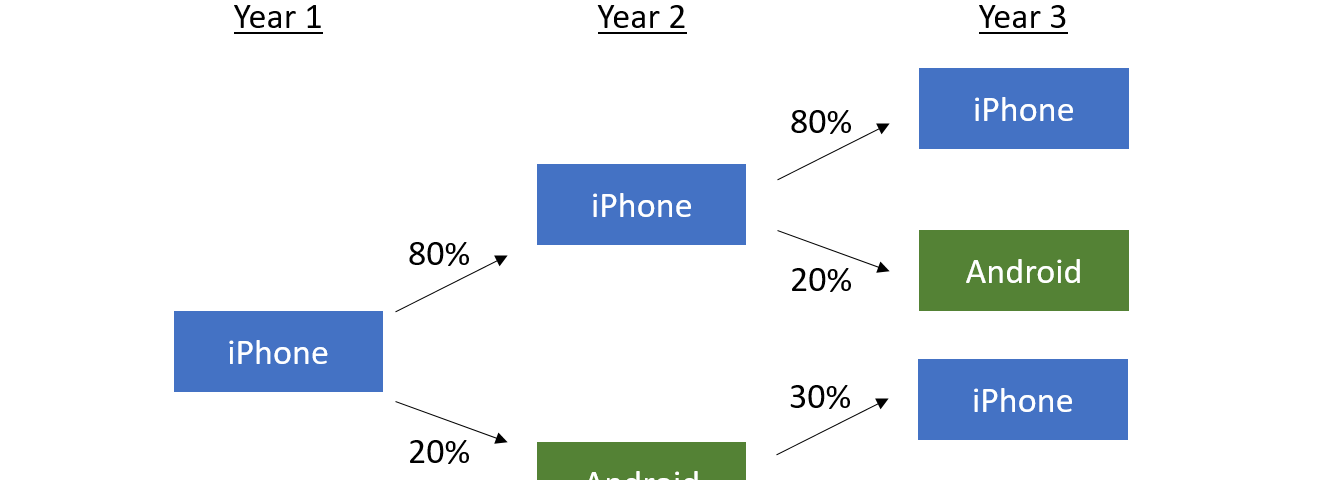
All stories published by Towards Data Science on April 26, 2020

Jim Fan on LinkedIn: Human creations are sometimes too advanced for GPT-4V to appreciate. 🤣…

AI #40: A Vision from Vitalik - by Zvi Mowshowitz

Latent Space: The AI Engineer Podcast — CodeGen, Agents, Computer Vision, Data Science, AI UX and all things Software 3.0 – Podcast – Podtail

RLHF: Reinforcement Learning from Human Feedback, by Ms Aerin

DeepMind: the existence proof for RL at scale, by Nathan Lambert

Deep learning is not the key to unlocking the Singularity, by Nathan Lambert
RLHF: Reinforcement Learning from Human Feedback, by Ms Aerin
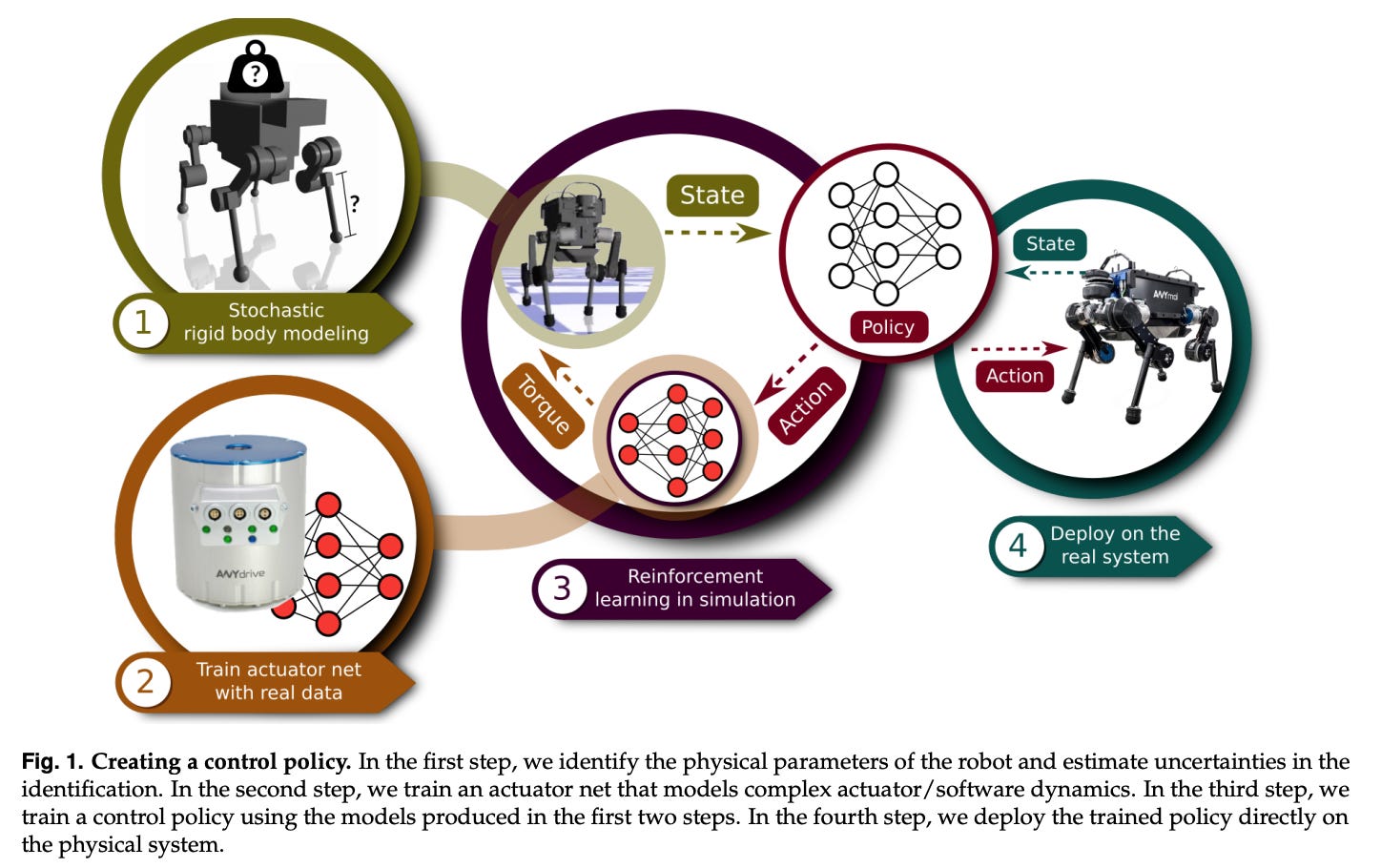
Pretraining quadrupeds: a case study in RL as an engineering tool

PDF) Machine Learning for Ancient Languages: A Survey

Nathan Lambert – Medium
Recomendado para você
-
 DeepMind's AlphaGo Zero and AlphaZero12 março 2025
DeepMind's AlphaGo Zero and AlphaZero12 março 2025 -
 How AlphaZero Works – Augmented Lawyer12 março 2025
How AlphaZero Works – Augmented Lawyer12 março 2025 -
 Question on the Alpha Zero research paper : r/chess12 março 2025
Question on the Alpha Zero research paper : r/chess12 março 2025 -
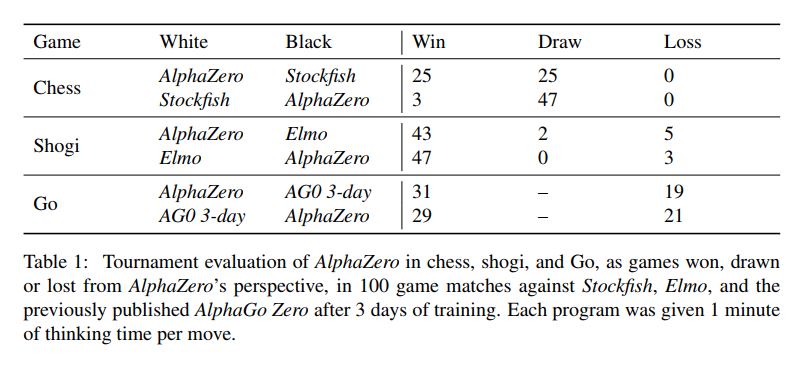 Dr. Rudolf Posch: Neural Network AlphaZero wins in Chess, Shogi and Go12 março 2025
Dr. Rudolf Posch: Neural Network AlphaZero wins in Chess, Shogi and Go12 março 2025 -
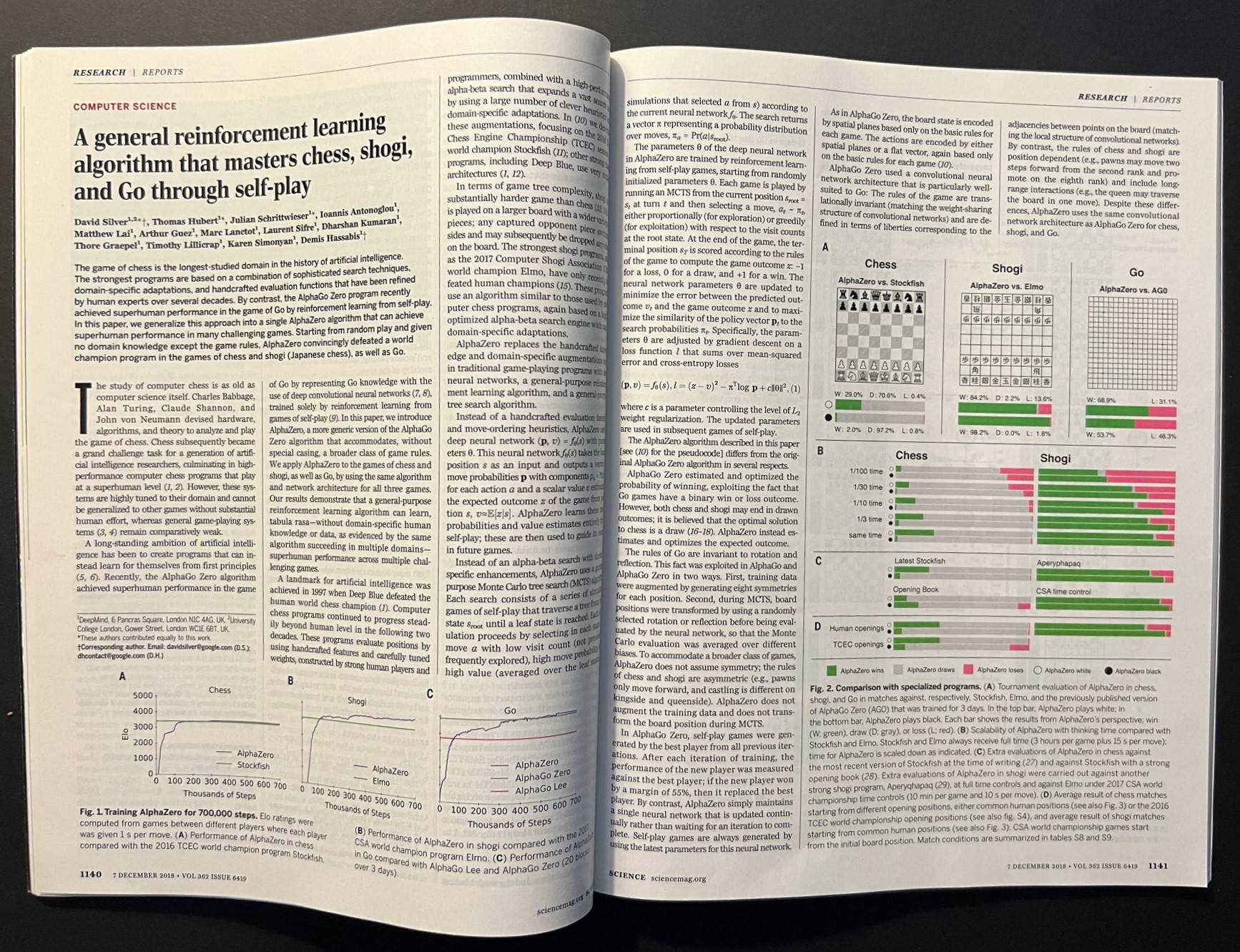 David Silver (et al.), A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. With: Garry Kasparov, Chess, a Drosophila of Reasoning. And with: Murray Campbell, Mastering Board games12 março 2025
David Silver (et al.), A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. With: Garry Kasparov, Chess, a Drosophila of Reasoning. And with: Murray Campbell, Mastering Board games12 março 2025 -
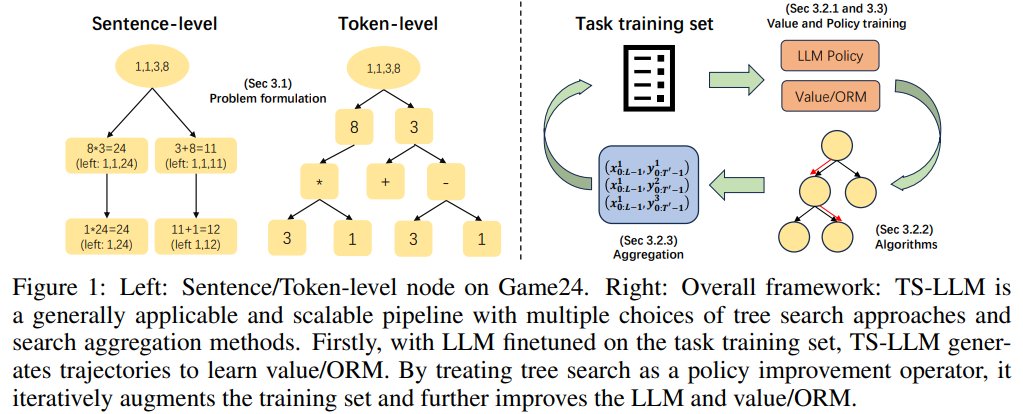 xidong feng on X: 🎉Excited to share our new work that tries to use AlphaZero-like tree search for LLM's decoding and training. We include a detailed pipeline and comprehensive experiments to show12 março 2025
xidong feng on X: 🎉Excited to share our new work that tries to use AlphaZero-like tree search for LLM's decoding and training. We include a detailed pipeline and comprehensive experiments to show12 março 2025 -
Alpha Kappa Alpha Sorority, Incorporated - Rho Xi Omega Chapter12 março 2025
-
 Alpha Zero one Multi-Collagen Powder 100g-grass fed12 março 2025
Alpha Zero one Multi-Collagen Powder 100g-grass fed12 março 2025 -
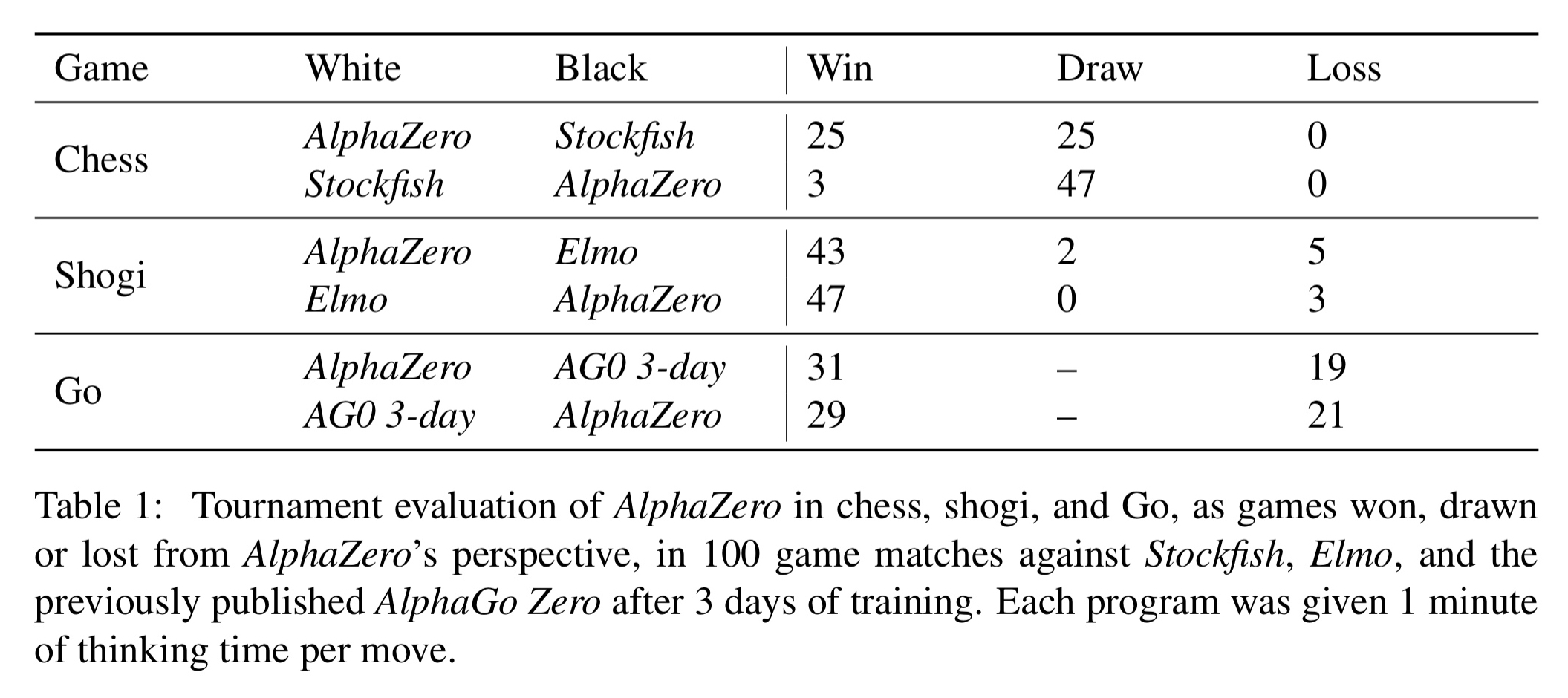 Mastering chess and shogi by self-play with a general reinforcement learning algorithm12 março 2025
Mastering chess and shogi by self-play with a general reinforcement learning algorithm12 março 2025 -
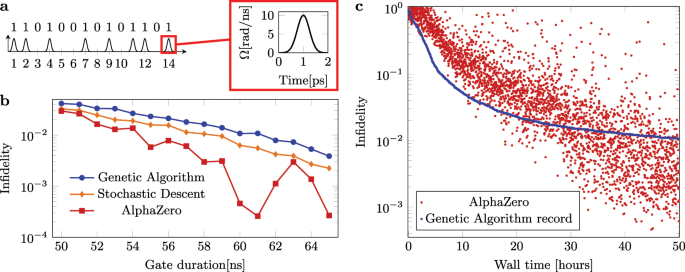 Global optimization of quantum dynamics with AlphaZero deep exploration12 março 2025
Global optimization of quantum dynamics with AlphaZero deep exploration12 março 2025

você pode gostar
-
 Futebol Americano Philadelphia Eagles12 março 2025
Futebol Americano Philadelphia Eagles12 março 2025 -
 Doors All the Entities New Doors Game Update Kids T-Shirt for Sale by TheBullishRhino12 março 2025
Doors All the Entities New Doors Game Update Kids T-Shirt for Sale by TheBullishRhino12 março 2025 -
 File:Sonic-the-hedgehog-3-the-super-sonic-lets-play.png12 março 2025
File:Sonic-the-hedgehog-3-the-super-sonic-lets-play.png12 março 2025 -
 🔥LANÇOU🔥EXECUTOR FLUXUS ATUALIZADO PARA CELULAR + SCRIPT PARA BLOX FRUITS12 março 2025
🔥LANÇOU🔥EXECUTOR FLUXUS ATUALIZADO PARA CELULAR + SCRIPT PARA BLOX FRUITS12 março 2025 -
2023 Happymod free robux combo age12 março 2025
-
 Name these old classic video games. Can you name all 15 games?12 março 2025
Name these old classic video games. Can you name all 15 games?12 março 2025 -
 13 Filmes de terror e suspense para assistir na HBO Max em 202312 março 2025
13 Filmes de terror e suspense para assistir na HBO Max em 202312 março 2025 -
 43- Team Waifu perfil by PiBeTrAiDoR on DeviantArt12 março 2025
43- Team Waifu perfil by PiBeTrAiDoR on DeviantArt12 março 2025 -
 Updated List of Chess FIDE World Cup Winners (2000-2023)12 março 2025
Updated List of Chess FIDE World Cup Winners (2000-2023)12 março 2025 -
 ICQ, o que é? Origem e história do famoso aplicativo de mensagens12 março 2025
ICQ, o que é? Origem e história do famoso aplicativo de mensagens12 março 2025