AlphaGo Zero Explained
Por um escritor misterioso
Last updated 26 abril 2025
Mastering the Game of Go without Human Knowledge
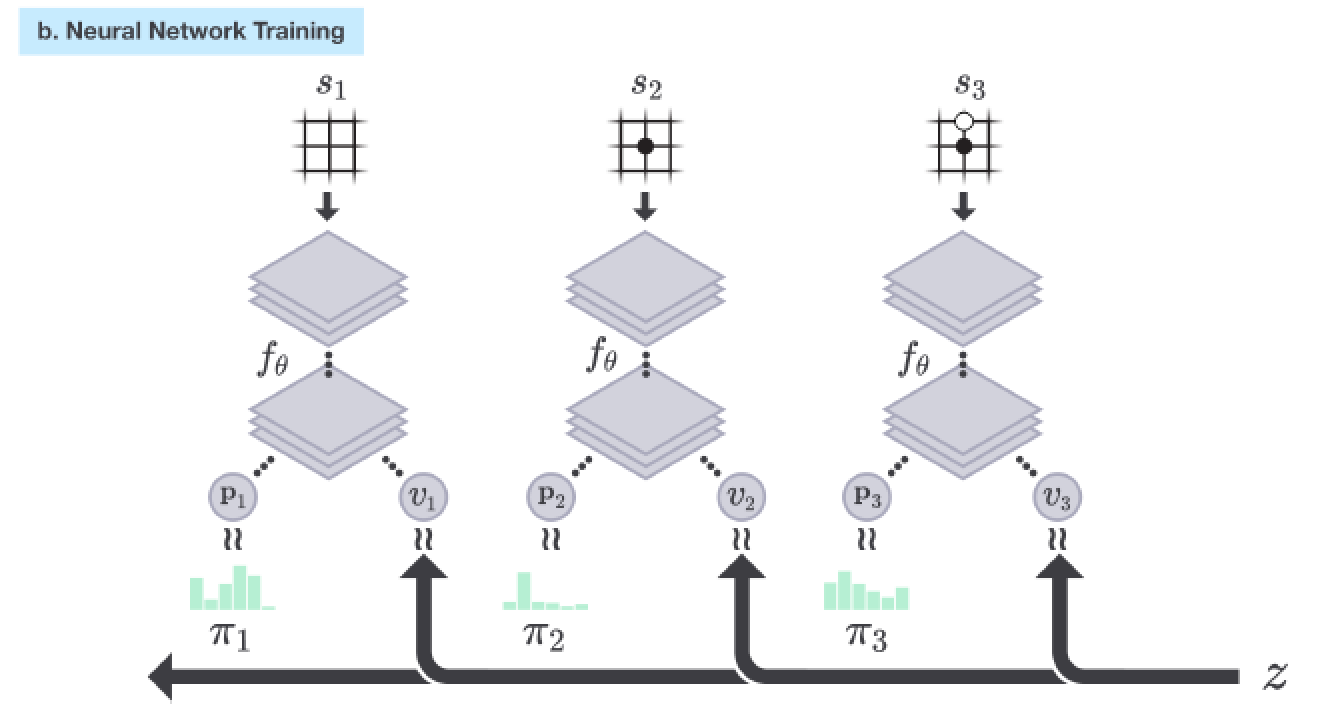
Self-play reinforcement learning in AlphaGo Zero. a The program plays a
AlphaGo Zero — a game changer. (How it works?), by Jonathan Hui

Why DeepMind AlphaGo Zero is a game changer for AI research
/cdn.vox-cdn.com/uploads/chorus_asset/file/6166173/DSCF3746.0.jpg)
DeepMind's Go-playing AI doesn't need human help to beat us anymore - The Verge
AI that learns how to win without knowing the rules - Techrecipe

Why DeepMind AlphaGo Zero is a game changer for AI research
AlphaGo Zero Explained

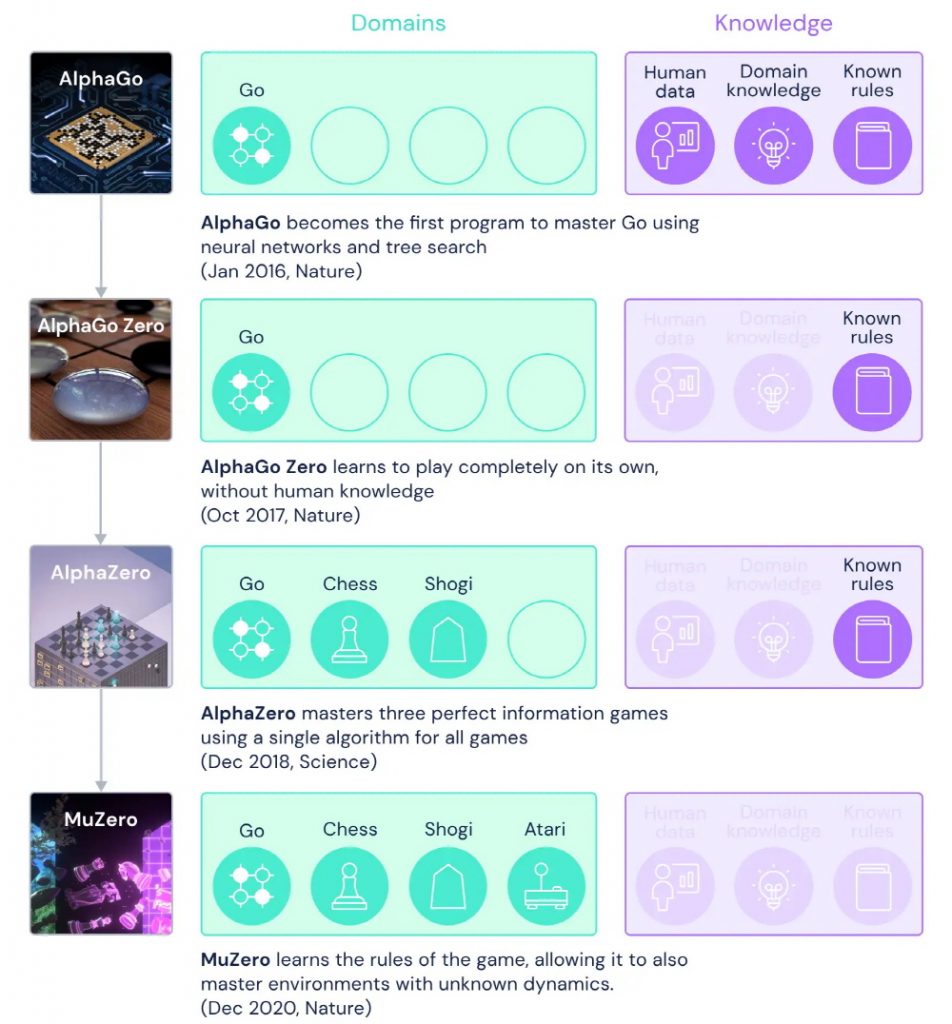
AlphaGo PDF, PDF, Game Theory
GitHub - tkhkaeio/AlphaZero: I researched and explained AlphaGo/AlphaGo Zero papers, which had beaten the world the game of Go champion in 2016, 2017. Especially, I applied Alpha Zero algorithm to Othello to
AlphaGo versus Lee Sedol - Wikipedia

Case study: AlphaGo

Deep Mind's AlphaGo Zero - EXPLAINED

AlphaZero Explained · On AI
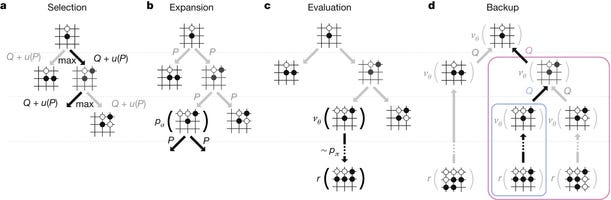
Summary of the AlphaGo paper. I found DeepMind's AlphaGo paper quite…, by gwk
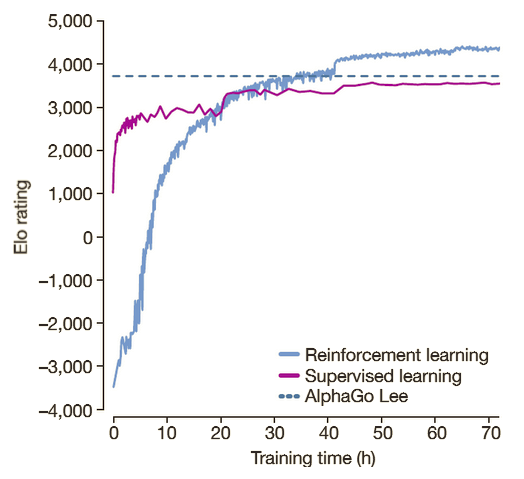
Empirical evaluation of AlphaGo Zero. a Performance of self-play
Recomendado para você
-
 New AlphaZero Paper Explores Chess Variants26 abril 2025
New AlphaZero Paper Explores Chess Variants26 abril 2025 -
 Checkmate: how we mastered the AlphaZero cover, Science26 abril 2025
Checkmate: how we mastered the AlphaZero cover, Science26 abril 2025 -
 AlphaZero - Wikipedia26 abril 2025
AlphaZero - Wikipedia26 abril 2025 -
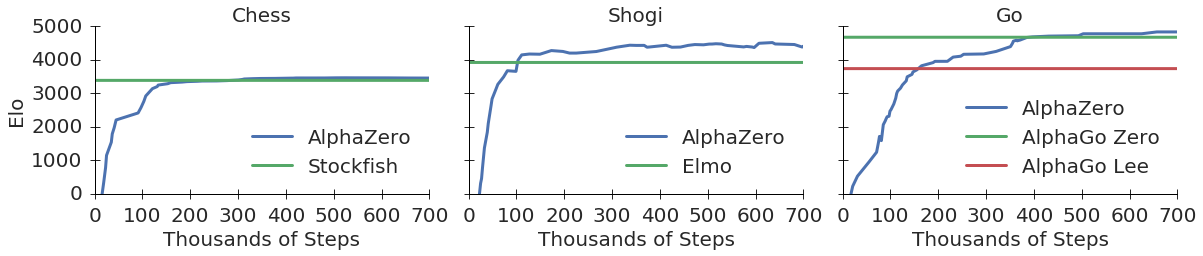 AlphaZero Explained26 abril 2025
AlphaZero Explained26 abril 2025 -
Alphazero Chess Download PNG - Google-Keresés26 abril 2025
-
 Diversifying AI: Towards Creative Chess with AlphaZero26 abril 2025
Diversifying AI: Towards Creative Chess with AlphaZero26 abril 2025 -
 Contributing to Leela Chess Zero. Creating the Caissa of Chess engines. - Leela Chess Zero26 abril 2025
Contributing to Leela Chess Zero. Creating the Caissa of Chess engines. - Leela Chess Zero26 abril 2025 -
 How the Artificial Intelligence Program AlphaZero Mastered Its Games26 abril 2025
How the Artificial Intelligence Program AlphaZero Mastered Its Games26 abril 2025 -
 Move over AlphaGo: AlphaZero taught itself to play three different games26 abril 2025
Move over AlphaGo: AlphaZero taught itself to play three different games26 abril 2025 -
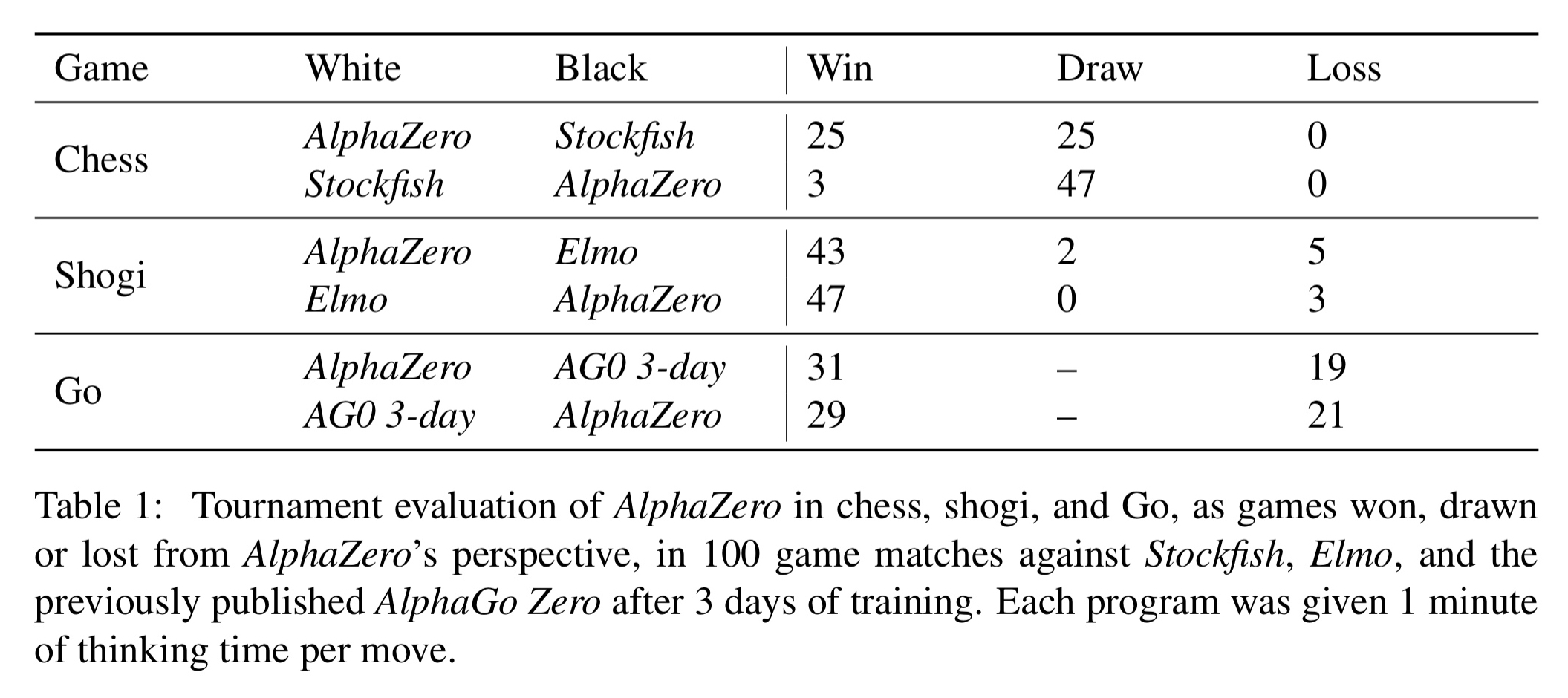 Mastering chess and shogi by self-play with a general26 abril 2025
Mastering chess and shogi by self-play with a general26 abril 2025
você pode gostar
-
 Mahjong 🕹️ Jogue no CrazyGames26 abril 2025
Mahjong 🕹️ Jogue no CrazyGames26 abril 2025 -
Shaders Packs for Minecraft PE – Apps no Google Play26 abril 2025
-
![Anime World Trello Link & Wiki [Official & Verified] [December 2023] - MrGuider](https://www.mrguider.org/wp-content/uploads/2023/07/Anime-World-Trello-Link-Wiki-Official-Verified.jpg) Anime World Trello Link & Wiki [Official & Verified] [December 2023] - MrGuider26 abril 2025
Anime World Trello Link & Wiki [Official & Verified] [December 2023] - MrGuider26 abril 2025 -
 Build A Board Game Clipart Set 2 {Zip-A-Dee-Doo-Dah Designs26 abril 2025
Build A Board Game Clipart Set 2 {Zip-A-Dee-Doo-Dah Designs26 abril 2025 -
 Curso de iniciação ao jogo de tabuleiro como ferramenta inovadora no ensino26 abril 2025
Curso de iniciação ao jogo de tabuleiro como ferramenta inovadora no ensino26 abril 2025 -
 SUPER SONIC VS SHADOW THE HEDGEHOG26 abril 2025
SUPER SONIC VS SHADOW THE HEDGEHOG26 abril 2025 -
/i.s3.glbimg.com/v1/AUTH_1f551ea7087a47f39ead75f64041559a/internal_photos/bs/2023/F/t/fx0Ar2S32J7hAAzMXSGA/arte-35-.png) Flamengo e Vasco fazem clássico no Brasileirão sob gestões26 abril 2025
Flamengo e Vasco fazem clássico no Brasileirão sob gestões26 abril 2025 -
 THEM Anime Reviews 4.0 - Golden Time26 abril 2025
THEM Anime Reviews 4.0 - Golden Time26 abril 2025 -
 Functional outcomes and quality of life at 1-year follow-up after an open tibia fracture in Malawi: a multicentre, prospective cohort study - The Lancet Global Health26 abril 2025
Functional outcomes and quality of life at 1-year follow-up after an open tibia fracture in Malawi: a multicentre, prospective cohort study - The Lancet Global Health26 abril 2025 -
 Download do APK de jogos bruxa - poção jogo 3 puzzle para Android26 abril 2025
Download do APK de jogos bruxa - poção jogo 3 puzzle para Android26 abril 2025
