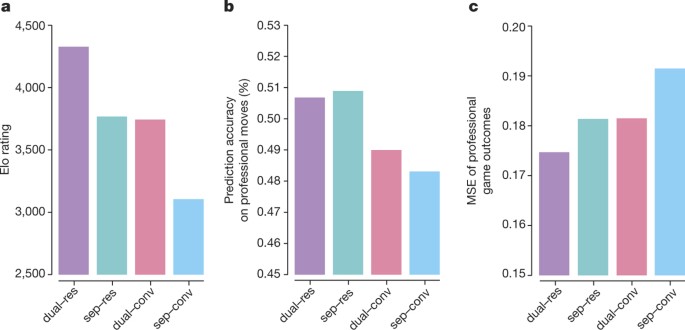
Training AlphaZero for 700,000 steps. Elo ratings were computed from
Por um escritor misterioso
Last updated 26 abril 2025


Training AlphaZero for 700,000 steps. Elo ratings were computed from

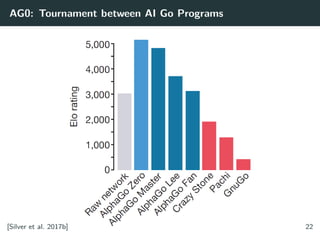
Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
When Alpha Zero is making seemingly bizarre moves in chess is it actually predicting what its opponent will do (calculating possibilities), or is it setting up its own attack/defense based on positional

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning

Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Mastering the game of Go without human knowledge

PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

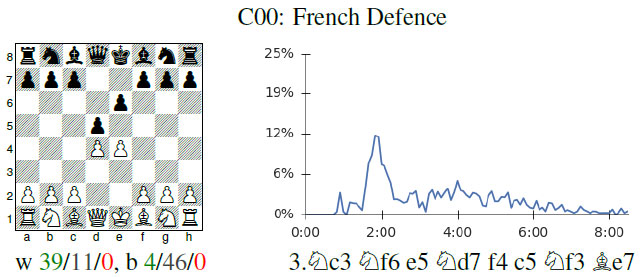
AlphaZero - Stockfish: French Defense, Classical Variation, Steinitz Variation (C14) : r/chess
AlphaZero
Recomendado para você
-
 AlphaZero on Carlsen-Caruana Games 1-826 abril 2025
AlphaZero on Carlsen-Caruana Games 1-826 abril 2025 -
 The future is here – AlphaZero learns chess26 abril 2025
The future is here – AlphaZero learns chess26 abril 2025 -
 AlphaZero, Vladimir Kramnik and reinventing chess26 abril 2025
AlphaZero, Vladimir Kramnik and reinventing chess26 abril 2025 -
 How did Google's AlphaZero beat the world's best chess computer?26 abril 2025
How did Google's AlphaZero beat the world's best chess computer?26 abril 2025 -
 Acquisition of chess knowledge in AlphaZero26 abril 2025
Acquisition of chess knowledge in AlphaZero26 abril 2025 -
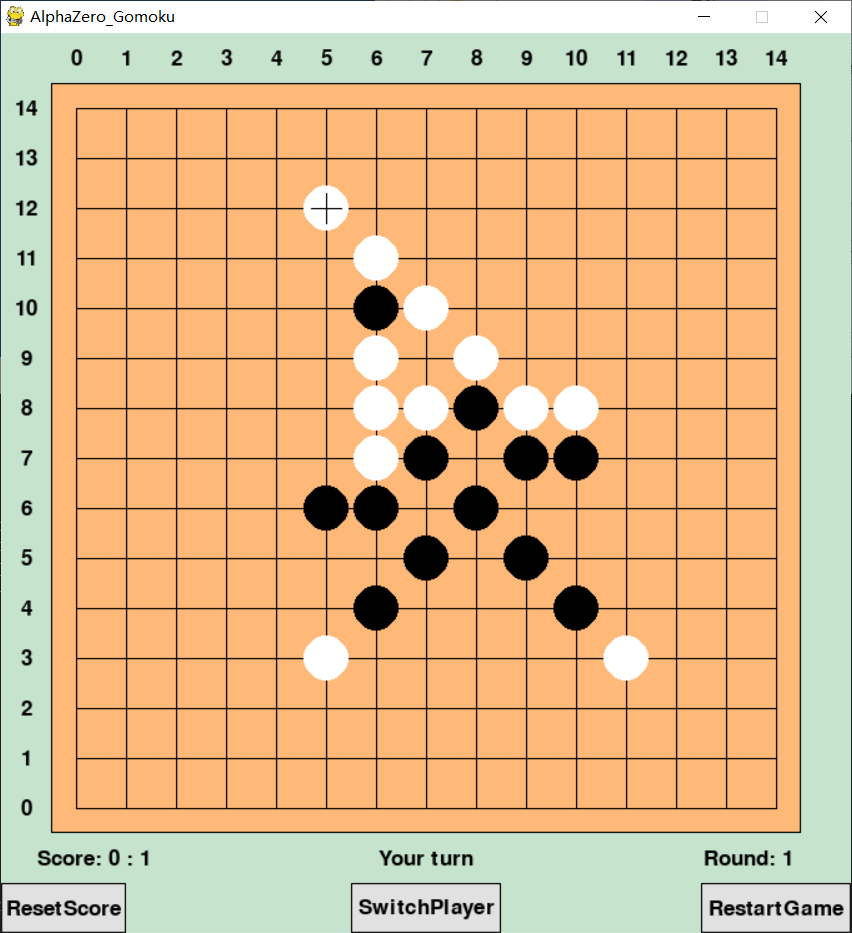 Alphazero Download26 abril 2025
Alphazero Download26 abril 2025 -
 The AlphaZero-FX network outperforms the vanilla version that uses26 abril 2025
The AlphaZero-FX network outperforms the vanilla version that uses26 abril 2025 -
 AlphaZero.jl download26 abril 2025
AlphaZero.jl download26 abril 2025 -
 Bagatur Chess Engine F-Droid - Free and Open Source Android App Repository26 abril 2025
Bagatur Chess Engine F-Droid - Free and Open Source Android App Repository26 abril 2025 -
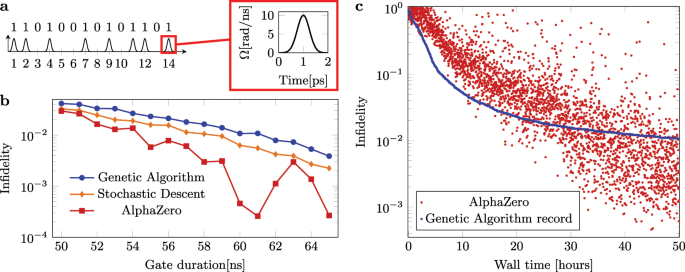 Global optimization of quantum dynamics with AlphaZero deep exploration26 abril 2025
Global optimization of quantum dynamics with AlphaZero deep exploration26 abril 2025
você pode gostar
-
 Mortal Kombat co-creator Ed Boon teases DLC characters with kryptic tweets26 abril 2025
Mortal Kombat co-creator Ed Boon teases DLC characters with kryptic tweets26 abril 2025 -
 react native - Cannot Login Using Facebook After Removed The App26 abril 2025
react native - Cannot Login Using Facebook After Removed The App26 abril 2025 -
 Hyper Tails, World of Sonic Online Wiki26 abril 2025
Hyper Tails, World of Sonic Online Wiki26 abril 2025 -
Quero Vingança Contra o NOVO PARTICIPANTE! - Creative Squad 326 abril 2025
-
8 Ball Billard - Pool Billards for Android - Free App Download26 abril 2025
-
Hotel Ling Bao - Phantasialand Erlebnishotel – Hotels auf Google26 abril 2025
-
 A BETA DE POKÉMON GOLD E SILVER +DOWNLOAD26 abril 2025
A BETA DE POKÉMON GOLD E SILVER +DOWNLOAD26 abril 2025 -
 Thanks for all you had did Roblox : r/roblox26 abril 2025
Thanks for all you had did Roblox : r/roblox26 abril 2025 -
WDN - World Dubbing News26 abril 2025
-
Blue Beetle26 abril 2025




